Dans le premier article de cette petite série d’articles, on a vu pourquoi certains éléments sont des semi-conducteurs, comment ils fonctionnent et comment on peut les doper avec d’autres éléments pour leur donner des propriétés plus intéressantes ou utiles.
Pour ce second article, on va voir comment ces semi-conducteurs peuvent former la brique élémentaire de l’informatique moderne : le transistor.
La Diode et le Transistor
La diode est l’équivalent beaucoup plus petite, beaucoup plus pratique, beaucoup plus robuste que les anciennes ampoules à vide utilisées dans les premiers ancêtres d’ordinateurs. Ces ampoules utilisaient une borne émettrice d’électrons à très haute tension et une autre borne qui les réceptionnait. L’ensemble était asymétrique et les électrons ne pouvaient passer que dans un seul et unique sens (le principe de la diode).
Des diodes tripolaires (triiode) au format d’anciens tubes à vide (source)
Ces ampoules à vide étaient grandes, chauffaient, nécessitaient des hautes tensions… bref, l’informatique méritait mieux que ça. Heureusement, depuis on a inventé les circuits intégrés : ce sont des semi-conducteurs gravés qui font office de composants électroniques. Ces derniers sont désormais beaucoup plus petits, ne chauffent pas ou peu et sont bien moins fragiles et moins chères.
Par exemple, le transistor est tellement miniaturisé que votre ordinateur ou votre téléphone en contient plusieurs centaines de millions, voire plusieurs milliards, sur une simple puce de silicium.
Quelques exemples de transistors simples en tant que composants pour l’électronique (source)
La diode, comme son nom laisse penser (le « di- »), est composé de deux morceaux de semi-conducteurs : un morceau de semi-conducteur dopé P, et un morceau dopé N (on parle de diode PN).
Le transistor, lui, est un composant à trois bornes qui est composé de deux diodes collées l’une à l’autre de façon à former une suite N-PP-N : le transistor NPN ou une suite P-NN-P (donc PNP).
Anatomie d’un transistor
Comme je l’ai dit au dessus, le transistor est un tripôle correspondant à une juxtaposition de semi-conducteurs dopés N et P. Dans ce qui suit, on prendra comme base le transistor NPN en silicium.
Dans les faits, c’est un sandwich de silicium P entre deux tranches de silicium N :
Schéma et symbole du transistor
Le fait que l’on utilise des semi-conducteurs dopés différemment, on observe plusieurs phénomènes dans le transistor, notamment aux jonctions NP et PN.
Souvenez-vous, les semi-conducteurs dopés N sont surchargés d’électrons : le cristal de semi-conducteur contient des électrons « libres » entre les atomes. Les semi-conducteurs dopés P contiennent des trous d’électrons : des emplacements où se trouve une liaison cristalline mais où il manque un électron.
Aux jonctions, et uniquement aux jonctions, certains électrons de la partie N va aller boucher les trous de la partie P.
On se retrouve donc avec les jonctions qui se retrouvent à la fois sans électrons libres et sans trous : les électrons du N sont partis boucher les trous du P. Cette jonction ne contient donc plus de charges conductrices introduites grâce au dopage :
Ce déplacement d’électrons au sein du cristal de silicium dopé va générer des régions chargées au niveau des jonctions : les zones N vont devenir positives (le phosphore se trouve ionisé positivement, car son électron en trop est parti) et les zones P de l’autre côté vont se retrouver négatives (le bore va se retrouver ionisé négativement, car son trou est bouché par un électron).
Si les électrons et les trous ne participent plus à la conduction du courant au niveau de ces jonctions, ils représentent donc une différence de charge au niveau moléculaire :
À ce stade, le transistor n’est pas encore branché dans un circuit : les zones chargées sur les jonctions sont présentes de façon naturelle au sein de la matière qui compose le transistor, simplement parce que des électrons se sont déplacés. Ce phénomène de productions de zones chargées au niveau des jonctions est cruciale pour le fonctionnement du transistor. En fait, c’est là que naissent toutes les propriétés électroniques des transistors.
Fonctionnement d’un transistor
Voyons ce qui se passe quand on branche le transistor dans un circuit.
Le transistor dispose de trois bornes :
le collecteur ;
la base ;
l’émetteur.
Le collecteur et l’émetteur sont techniquement symétriques. La base est est un peu particulière.
Commençons par brancher le collecteur et l’émetteur dans un circuit et à mettre le courant (on considère que la base n’est reliée à rien du tout).
Les premiers électrons qui vont arriver au collecteur vont être naturellement attirés par la région positivement chargée près de la jonction NP.
Une fois que cette région sera occupée par les électrons, ces derniers vont se retrouver devant à un mur : ils seront repoussés par la région négative dans la partie P du transistor. Les électrons ne peuvent donc pas passer vers l’émetteur.
De l’autre côté, les électrons de l’émetteur finissent par être aspirés dans le circuit, mais ils sont également attirés par la région positivement chargée à la jonction PN. De ce fait, le courant ne passe pas là non plus.
À ce stade, le transistor bloque complètement la circulation du courant.
(Évidemment, si on augmente la tension aux bornes C et E du transistor, le courant finira par passer quand-même : la différence de potentiel du circuit sera plus forte que les effets de répulsion qui empêchent les électrons de passer, mais dans ce cas là, ça correspondra au claquage du composant et résulterait également en sa destruction, ce qui n’est donc pas un comportement normal ni souhaité.)
Maintenant, mettons la base du transistor sous tension et observons ce qui se passe :
À cause de cette tension positive sur la base, des électrons commencent par être retirés de la base.
La conséquence de cela, c’est que les électrons du collecteur ne subissent plus de répulsion et ils peuvent maintenant se mettre à circuler sous l’effet de la tension principale entre le collecteur et l’émetteur.
En arrivant sur l’émetteur, les électrons vont boucher les trous (qui sont positifs), puis vont pouvoir passer dans le circuit.
La simple présence du courant sur la base suffit à supprimer la barrière d’électrons qui empêchait le courant principal entre le collecteur et l’émetteur de passer. Si on supprime ce courant de la base, les électrons qui vont arriver par le collecteur vont s’arrêter au niveau des trous dans la région P et finir de nouveau par bloquer le courant entre le collecteur et l’émetteur !
On a donc un comportement très particulier :
en appliquant une petite tension à la base, le courant principal entre le collecteur et l’émetteur peur passer ;
en supprimant cette tension à la base, le courant entre le collecteur et l’émetteur est coupé.
Ce comportement peut sembler anodin, mais il ne l’est pas : cet effet, parfois nommé effet transistor permet de contrôler un courant principal (circuit CE) avec un petit courant secondaire (sur la borne B). Il s’agit donc d’un sorte d’interrupteur électronique.
Le transistor est un interrupteur contrôlé électroniquement, sans partie mécanique.
Vous devinez peut-être la suite : que se passe-t-il si on branche plusieurs transistors à la suite, avec la sortie d’un transistor branché à la base d’un autre : ainsi, un transistor peut contrôler le suivant.
Les portes logiques
Si on met deux transistors à la suite, le second dépendra du premier quelque soit son état (bloquant ou passant).
Une chose est sûre cependant, c’est que pour qu’il laisse passer le courant, il faut obligatoirement que le premier laisse passer le courant lui aussi :
si les entrée A et B sont nulles (tension nulle), alors la sortie est nulle ;
si A est nulle mais que B n’est pas nulle, alors la sortie est nulle ;
si B est nulle mais que A n’est pas nulle, alors la sortie est nulle ;
si A et B ne sont pas nulle, alors la sortie n’est pas nulle (la tension à la sortie est (ici) de 5 V).
On appelle ce dispositif une « porte ET », dans le sens où le courant passe uniquement si l’entrée A et l’entrée B sont sous tension.
Il existe aussi la porte OU, où le courant passe à la condition que l’une des entrées au moins est sous tension.
Les portes logiques dans ce genre existe sous plein de formes. On a vu ET, j’ai mentionné OU. Citons aussi la porte NON (dont la sortie est l’inverse de l’entrée), la porte NON-ET (qui inverse la sortie d’une porte ET), la porte NON-OU, la porte OU-Exclusif (qui est une porte où l’une des entrées seule doit être sous tension, mais surtout pas les deux).
Ces portes logiques permettent de comparer des entrées (A et B) : si les deux entrées sont à 0 V, alors la porte ET ou OU afficheront également 0 V en sortie. Mais la porte Non-OU ou Non-ET afficheront 5 V en sortie.
Ces portes constituent le début des fonctions opératoires de base en électronique.
Avec quelques-unes de ces portes logiques, on commence à faire des calculs encore plus évoluées. Par exemple, on peut faire un additionneur sur deux bits avec retenue à l’aide de seulement cinq portes logiques :
L’addition se fait ici en binaire. Si je branche les bornes A et B, j’obtiens en sortie l’addition de A et B :
La borne Re, c’est pour brancher la sortie Rs (la retenue) d’un montage précédent identique. En grand nombre, ces montages entiers mis bout à bout permettent de faire des additions binaires beaucoup plus grandes !
Différents agencements permettent de faire des convertisseurs, des multiplicateurs, des diviseurs… Toutes les fonctions mathématiques de base, en fait, et avec elles, toutes les applications imaginables dans les programmes d’ordinateur.
Croyez-le bien : en grand nombre et assemblés, ce genre de montages, composés uniquement de transistors en silicium dopé, sont à la base des processeurs et des les composants actifs dans tous les ordinateurs, smartphones et systèmes numériques !
Dans le prochain article, je parlerai d’une fonction un peu particulière obtenue avec les transistors : la fonction mémoire. Des clés USB aux cartes mémoires en passant par les disques durs SSD, tous ces systèmes de stockage de données utilisent en effet des transistors pour stocker les données numériques sur le long terme.
Les précédents articles parlaient de la nature d’un semi-conducteur et son fonctionnement et comment on les utilisait pour créer des transistors.
Désormais on va voir comment utiliser les transistors pour faire un composant essentiel à nos ordinateurs et nos appareils numériques : la mémoire.
Les disquettes et les disques durs à plateau stockent l’information de façon magnétique : les octets sont écrits sous la forme de minuscules aimants sur le disque. En lisant les intensités du champ magnétique sur le disque, on retrouve alors nos octets initiaux.
Pour la mémoire flash, présente les clé USB, les cartes mémoire ou les lecteurs SSD, l’information est stockée à l’aide de transistors.
Ce qui est intéressant ici c’est que l’information stockée persiste électriquement au sein du composant même en l’absence d’alimentation électrique. Ceci est le contraire de la mémoire utilisée dans les barrettes de mémoire vive (RAM) qui perdent leur contenu quand l’ordinateur est hors-tension.
MOSFET à grille flottante (ou FGMOS)
À vos souhait.
Le MOSFET (pour Metal Oxide Semiconductor Field Effect Transistor, ou transistor à effet de champ à oxyde métallique) est un type particulier de transistor. Le fonctionnement de ces transistors est un peu différent mais l’effet obtenu est le même que celui que l’on a vu dans l’article précédent.
On a vu que la base du transistor est une borne qui permet de contrôler le transistor en lui appliquant une tension électrique. Pour le transistor à effet de champ, ce n’est plus un courant électrique qui vient « aspirer » les électrons qui bloquaient le courant principal, mais un champ électrique distant qui vient les attirer. La borne elle-même est isolée du circuit principal :
Si la base n’est soumise à aucune tension, le transistor à effet de champ est bloquant.
Par contre, quand on applique une tension électrique sur la base, il va se créer un champ électrique assez puissant pour repousser les charges positives (les trous) et attirer toutes les charges négatives (les électrons). Il se forme donc une zone entièrement conductrice entre le collecteur et l’émetteur où le courant va pouvoir passer :
Ici on a simplement reproduit l’effet transistor mais avec un système différent. Il n’y a pas encore d’effet mémoire.
Pour obtenir un système de mémoire, il faut aller plus loin : il faut ajouter un conducteur entre deux couches d’isolants, comme ceci :
La partie en noir est un simple morceau de conducteur. On l’appelle « grille flottante » (floating gate) parce qu’elle est isolée du reste. C’est cette grille flottante qui va permettre l’effet mémoire.
La grille flottante : origine de l’effet mémoire
Si on ne considère que la grille flottante, elle peut être dans deux états :
chargée électriquement, en électrons (comme un condensateur) ;
non-chargée électriquement (neutre en charges).
Si cette grille est chargée en électrons, ces derniers vont repousser tous les électrons du semi-conducteur P. Si on applique une tension sur la base, la champ électrique produit ne suffira pas à attirer les électrons dans le bloc P, car la grille lui en empêche.
Au contraire, si la grille est neutre (déchargée) et qu’une tension est appliquée sur la base, le champ électrique pourra attirer les électrons de la partie P sans que ceux-ci soient repoussés : le transistor devient alors passant :
L’intérêt de tout ça, c’est que puisque la grille est isolée électriquement, son état va persister sur le long terme : c’est là que se joue l’effet mémoire.
Lecture et écriture
Lecture dans la mémoire
La phase de lecture est assez rapide et plutôt simple : il suffit de voir si le transistor est bloquant ou passant.
En effet, le simple fait de connaître l’état du transistor permet de déduire l’état de la charge sur la grille flottante.
Le transistor est passant (bit = 1) : la grille est déchargée ;
Le transistor est bloquant (bit = 0) : la grille est chargée en électrons.
Et c’est tout ce qu’il y a à faire pour lire le contenu d’un seul bit d’une mémoire de type FG-MOSFET.
Écriture dans la mémoire
Pour l’écriture, c’est une toute autre histoire. En effet, la fonction mémoire est assurée par un composant électrique isolé du reste du circuit. À priori, modifier cette charge n’est pas possible. Mais il y a une astuce, et pour ça il faut faire appel à la physique quantique et l’effet tunnel.
En physique quantique, comme l’a montré Schrödinger, les électrons comme toutes les particules peuvent être vues comme une onde. Onde et particule sont en fait différentes approches pour visualiser une seule et même entité (un électron).
Un électron est alors modélisé par une fonction d’onde dont l’amplitude, fixe, correspond à son énergie. L’électron peut se déplacer tant qu’il ne rencontre pas un champ d’énergie plus élevé, qui constitue alors ce qu’on appelle « une barrière de potentiel [énergétique] » :
(source)
Il se trouve que la couche d’isolant entre la grille flottante et la borne B constitue une barrière de potentiel de ce type : c’est la raison pour laquelle l’électron ne peut pas quitter la grille flottante en passant par la couche d’isolant.
Néanmoins, d’après l’équation de Schrödinger, la fonction d’onde ne s’arrête pas de façon nette devant la barrière de potentiel : en réalité, l’onde pénètre dans la barrière. Dans les fait, l’onde pénètre faiblement et son énergie décroît de façon exponentielle à l’intérieur de la barrière.
Ainsi, si la barrière de potentiel n’est pas épaisse, l’énergie de la fonction d’onde est non-nulle quand elle arrive de l’autre côté de la barrière de potentiel : l’électron arrive à s’échapper de l’autre côté :
Concrètement, dans la cas d’une barrière étroite, une partie de l’onde finit par s’échapper de l’autre côté de la barrière. De façon simplifiée, dans le cas de la grille flottante, c’est comme si des électrons traversent la couche d’isolant et finissent par décharger la grille flottante. Ce n’est pas ce qu’on veut.
Si on utilise une barrière plus large, alors l’onde s’affaiblit tellement face à la barrière de potentiel, que dans les faits, rien ne passe de l’autre côté : la grille peut alors rester chargée des années durant.
Ok, donc on sait qu’il faut utiliser une barrière large pour empêcher la mémoire de s’effacer avec le temps. On comprend qu’il faut donc utiliser une épaisseur suffisante d’isolant entre la borne de la base et de la grille. Mais comment on fait pour modifier la charge de la grille ?
Et bien on va réduire la barrière de potentiel lors de l’écriture et l’élargir pour le stockage à long terme, sans toucher à l’épaisseur physique de la couche d’isolant.
Pour parvenir à ça, on va appliquer une tension importante sur la base.
En simplifiant, ceci va élever le niveau d’énergie des électrons et déformer la barrière de potentiel pour qu’elle soit moins épaisse. Selon le signe de la tension (positive ou négative), les électrons passeront de la base vers la grille flottante (chargement de la grille) ou dans le sens inverse (déchargement), simplement par effet tunnel.
C’est donc un comportement issu purement de la physique quantique qui permet d’écrire dans la mémoire d’une clé USB.
Une autre solution (utilisé dans d’autres types de mémoire) est d’utiliser l’injection d’électrons chauds de la partie centrale P du transistor vers la grille flottante en leur donnant une vitesse (=énergie) suffisante pour leur permettre de traverser la couche isolante. Le qualificatif de « chaud » réfère l’énergie élevée des électrons.
Limites de ce type de mémoire
Si la lecture d’un bit de la mémoire est sans réelle contrainte technique, la phase d’écriture impliquent l’emploi de hautes tensions ou de conditions plutôt extrêmes pour le transistor. C’est là une des raisons qui fait que le nombre de cycles d’écriture des lecteurs SSD est limité.
Une autre limitation, c’est comme on a vu, le fait que la couche d’isolant doit être suffisamment épaisse pour éviter que les électrons ne s’échappent tout seuls de la grille. L’épaisseur de l’isolant constitue une des limites à la miniaturisation des composants.
Le même problème est d’ailleurs présent dans pratiquement tous les transistors, qu’ils soient dans un module mémoire ou pas : si l’architecture des transistors est trop petite, les électrons finissent par passer d’une borne à l’autre sans rien faire, simplement à cause de l’effet tunnel.
Mémoire NAND ou NOR ?
On a vu ce-dessus comment fonctionnent ou comment lire ou écrire un seul bit dans un seul transistor. Dans la réalité, la mémoire informatique vient sous la forme de modules avec plusieurs milliards de transistors. C’est la façon d’organiser ces transistors entre-eux qui varie selon le type de mémoire.
Si l’on utilise des transistors en série, on obtient de la mémoire NAND (nom donné à cause des portes NAND, où les deux transistors sont en série). Si on place les transistors en parallèle, on obtient de la mémoire NOR (dont le nom provient lui-aussi de l’analogie avec les portes NOR, où les deux transistors sont en parallèle).
Les deux types de mémoire ont chacun leurs avantages : la NOR est plus rapide mais la NAND permet une densité d’information plus importante.
Elles ont des applications différentes également : la mémoire NOR est utilisée quand la quantité d’information à stocker n’est pas grande ou bien si la vitesse est cruciale : mémoire cache des CPU (très rapide) ou mémoire des systèmes embarqués, par exemple. La mémoire NAND est utilisée dans les disques durs SSD, les clés USB et les cartes mémoire, là où la densité d’information est un facteur (commercial) important.
Un googol est un nombre représentant une quantité, tout comme les quantités « dizaine » ou « centaine ». La particularité ici est que le googol est un nombre plutôt grand puisque c’est un 1 suivi de cent zéros.
On peut l’écrire et ça donne ceci : 10 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000.
Mais pour des raisons évidentes, on l’écrit plutôt sous sa forme exponentielle : $10^{100}$.
Ce nombre est plus grand que le nombre d’atomes dans l’univers, qui est estimé à $10^{80}$.
Pour voir la grandeur de ce nombre, on peut par exemple utiliser les combinaisons ou les arrangements. Par exemple, en essayant de dénombrer toutes les parties possibles pour un jeu d’échec. Ce nombre a été calculé et vaut environ $10^{120}$, soit 100 milliards de milliards de googol.
C’est pas mal, non ?
Mais il y a mieux. Il y a le googolplex.
Un googolplex est un nombre encore plus grand : c’est un 1 suivi d’un googol de zéros. Un 1 suivi de $10^{100}$ zéros.
Je vous le dis tout de suite : il n’y a rien qui puisse être compté en googolplex. Ce nombre ne sert pas à grand chose, mais il est intéressant quand même, surtout quand on essaye de l’écrire (comme j’ai fait pour le googol un peu plus haut).
En fait, je vous laissez l’écrire en entier, moi je n’y arriverai pas.
Non, vraiment, je vous regarde.
Voici pourquoi je vous laisse faire : un googolplex est un nombre si immense que rien que pour l’écrire, le nombre d’atomes dans l’univers ne suffit pas. Il y plus de « 0 » dans l’écriture de ce nombre que d’atomes dans l’univers. Il faudrait environ cent milliard de milliard d’univers comme le nôtre pour avoir un atome par « 0 ».
Et encore, soyons bien clairs : tout ceci ne servira que pour écrire le googolplex ; et ça ne représente pas le googolplex lui-même !
La seule représentation possible, c’est celle avec les puissances : $10^{googol}$ ou $10^{10^{100}}$.
On peut également l’écrire de façon plus remarquable $10^{10^{10^{10}}}$, qui se comprime alors à son tour en $10\uparrow\uparrow4$.
Enfin, comme si ça ne suffisait pas, le googolplex n’est pas le plus grand nombre imaginé ou encore nommé.
Ok, il suffirait de parler de « deux googolplex » pour en faire un plus grand, mais d’autres nombres tels que le nombre de Graham ou le nombre de Skewes sont bien plus grands (mais moins marrants à prononcer, c’est vrai).
Oh et pour le dire : l’entreprise « Google » tire son nom de ce nombre, et le siège social de Google se nomme le Googleplex aussi. Mais ces derniers n’ont rien inventé de ce côté là :).
On entend parfois parfois de la « matière exotique » ou d’« atomes exotiques ». Je ne parlerais ici que de la seconde (le reste sera pour une autre fois).
Si les atomes normaux sont connus de tous, avec leurs protons, leurs neutrons et leurs électrons, les atomes exotiques sont des formations atomiques un peu particulières.
Je vais d’abord avoir besoin de faire un bref point sur les atomes ordinaires et le modèle standard de la physique quantique.
Les atomes
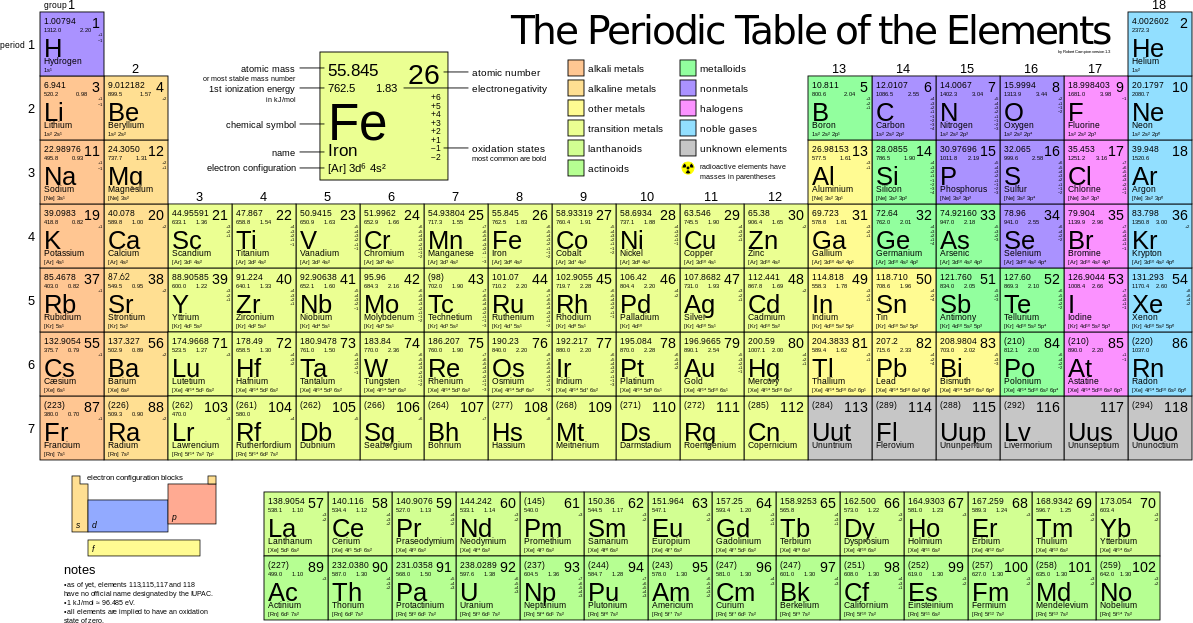
Je pense que tout le monde est plus ou moins familier avec ce tableau :
↑ Le tableau périodique des éléments — (source)
Toute la chimie, tous les objets, toute la biologie et la vie, vous et moi sont composé d’éléments présents uniquement dans ce tableau.
Les atomes exotique donc, c’est quelque chose de bien différent de ce que nous connaissons et, je vous le dis tout de suite, on ne risque d’en trouver ni dans la nature ni dans les magasins (en tout cas pas dans un futur proche et probablement pas dans notre univers).
Le modèle standard
En physique quantique, on parle du modèle standard pour définir et classer les différentes particules élémentaires de la matière qui existent :
↑ Les particules du modèle standard — (source)
On retrouve, tout en bas à gauche, l’électron. Le proton et le neutron sont formés des quarks up et down (3 chacun : 2 up + 1 down et 1 up + 2 down respectivement). Enfin lors de la désintégration radioactive de certains atomes il est parfois émis un neutrino électronique. Ces quatre particules sont toutes dans la première colonne du tableau.
Maintenant, si on considère la dernière ligne, on voit que les caractéristiques spin et charge de l’électron, du muon et du tau sont identiques. Seule la masse (ou l’énergie) varie. Chaque ligne regroupe en fait des particules ne différant que par leur masse et chaque colonne regroupe les éléments par « génération » selon la masse ou l’énergie : la première colonne regroupe les basse énergie, la seconde d’énergie moyenne et la dernière de haute énergie.
Fait d’électrons, de protons et de neutrons, nos particules et notre monde correspondent à la basse énergie du modèle standard. Toute la physique que l’on observe, incluant ce qui se passe dans le tableau périodique, la chimie ou les centrales nucléaires et le cœur des étoiles concerne cette physique de basse énergie. La basse énergie est celle qui est la plus stable et c’est sûrement pour ça que notre univers est composé presque uniquement de ces particules là.
D’autres univers pourraient être fait des niveaux d’énergie supérieurs au notre, mais on n’a pas encore de quoi les observer. On observe en revanche des particules isolées de moyenne et haute énergie ! Par exemple, quand les rayons cosmiques très énergétiques frappent l’atmosphère, une partie de l’énergie est transformée en particules hautement énergétiques : des muons.
Le muon est l’équivalent plus énergétique de l’électron, et, malgré sa durée de vie de seulement 2,2 µs, on est capable de faire des atomes avec !
C’est ce genre d’atomes, constitué d’un assemblage de particules que l’on n’a pas l’habitude de voir, qu’on nomme « atomes exotiques ».
Les atomes exotiques
L’hydrogène muonique
Je viens de le dire : il est possible de remplacer un électron par un muon, vu qu’il a la même charge.
Si l’on prend un proton que l’on associe à un muon, on obtient un atome d’hydrogène muonique.
Étant donnée que le muon est bien plus lourd que l’électron, le muon qui tourne autour du noyau est sur une orbitale bien plus proche de ce dernier et l’atome est beaucoup plus petit.
Cette particularité a plusieurs applications potentielles, comme la fusion nucléaire froide catalysée par muons. Normalement, pour faire fusionner des atomes, on doit les chauffer à des températures proches de ce que l’on trouve dans le cœur du Soleil (15 millions de degrés) si ce n’est beaucoup plus si on veut s’affranchir de la fusion probabiliste par effet tunnel, auquel cas il faut chauffer à près de 100 millions de degrés.
Ces températures sont nécessaires pour permettre à deux atomes et leurs noyaux de se rapprocher suffisamment pour fusionner. L’atome d’hydrogène muonique étant plus petit, il est plus simple de le fusionner et les températures requises sont moins hautes. L’un des plus gros problèmes pour un réacteur nucléaire à fusion froide catalysée par muons, c’est la durée de vue trop courte des muons (2,2 µs).
Le muonion
Les anti-particules sont opposées à nos particules selon divers caractéristiques quantiques dont la charge. Chaque particule se voit associer une anti-particule : l’électron avec son anti-électron (ou positron) ou le neutrino électronique avec l’anti-neutrino électronique sont les plus courantes car rencontrées dans la désintégration radioactive depuis longtemps.
Les muons ont aussi leur anti-particules : l’anti-muon. Sa charge est alors positive et est donc la même que le proton ou le positron.
Devinez quoi ? On peut remplacer un proton par un anti-muon ! Si on fait ça dans un atome d’hydrogène, on obtient un électron orbitant autour d’un anti-muon : le muonium.
Cet atome exotique, découvert déjà en 1960, possède même son propre symbole chimique : Mu (informel).
Cet atome exotique conserve (grâce à l’électron) les propriétés chimiques de l’hydrogène, et on a réussi à faire de l’eau muonique appelé hydroxyde muonique (HOMu), du chlorure de muonium (MuCl) ou du méthane contenant du muonium : le muoniométhane.
Encore une fois, tous ces atomes ont une durée de vie très courte à cause de l’anti-muon qui est très instable (et qui finit par se désintégrer spontanément après 2,2 µs en moyenne).
Les oniums : positronium et protonium
Un onium est une structure atomique où une particule chargée orbite autour de son anti-particule, de charge opposée (mais de masse identique).
Si l’électron orbite un positron, on obtient un atome de positronium. On a bien deux ici particules de charges opposées, mais contrairement à l’atome classique où le noyau est environ 1 000 fois plus lourd que l’électron on a ici une particule et son anti-particule de masse identique. Les deux sont donc pris dans une sorte de danse autour d’un barycentre commun :
↑ Schéma du positronium — (source)
Comme le muonium, le positronium a été synthétisé (depuis 2007), elle possède un symbole « Ps » et on a prédit des molécules positroniques, où cet atome exotique remplace un atome d’hydrogène : le PsH, le PsCl, le PsLi ou encore le Ps2 ont été observées.
Ces molécules et le positronium lui-même sont très instables (durée de vie de 100 ns) et se terminent par une annihilation matière-antimatière.
À la place de l’électron, on peut prendre le proton et l’antiproton : l’atome exotique ainsi obtenu est le protonium, dont le symbole est pp (reprenant le symbole « p » du proton et le « p-barre » de l’anti-proton).
Cet atome exotique a la particularité d’être le théâtre d’une bataille entre l’interaction forte et l’interaction électromagnétique. Là aussi cet ensemble est très instable et se termine en annihilation matière-antimatière.
Le pionium
J’ai dit plus haut que le proton et le neutron sont chacun formés de 3 quarks. Ce sont dès lors des baryons.
Des assemblages de seulement 2 quarks sont appelés des mésons et on peut former des atomes exotiques avec des mésons !
L’une des catégories de mésons sont les mésons-π (Pi), qui existe en trois exemplaires : π⁺, π⁻, π⁰.
Quand on fait un atome exotique avec le méson-π⁺ et le méson-π⁻ orbitant l’un autour de l’autre, on obtient un pionium.
Considérant qu’il existe 2 formes de quarks de basse énergie (up et down) et que chacun possède sont antiparticules (anti-up et anti-down) et qu’on a la même chose pour les quarks d’énergie moyenne et élevée, on obtient toute une collection de mésons différent : pions (π⁺, π⁻, π⁰) kaons (K+, K−, K⁰ Ks⁰, Kl⁰), Êta (plusieurs variantes là aussi)… et autant d’anti-mésons. Tous sont susceptibles de former des atomes exotiques, même si très peu ont encore été synthétisées ou observées.
En plus du pionium, on peut parler de l’hydrogène kaonique : c’est un proton autour duquel il orbite un kaon K⁻. Si on avait deux kaons à charge opposée, on parlerait de kaonium, mais ils n’ont pas encore été observés.
Atomes hypernucléaires
Quand on regarde le tableau du modèle standard, on peut dire que le quark strange « s » est au quark down ce que le muon est à l’électron. Or, le quark down est un composant des nucléons que sont le neutron et le proton.
Vous le devinez : on peut faire un nucléon contenant un quark strange : ce sont alors des hypérons, comme le Σ (sigma), le Ξ (xi) ou le Ω (oméga).
Si cet hypéron est placé dans un atome à la place d’un nucléon, alors on obtient un atome hypernucléaire.
En raison de la forte masse (pour une particule, hein) des quark strange, ces derniers sont très compliqués à produire et aussi très instables (durée de vie de l’ordre de la nanoseconde) et finissent pas se désintégrer en énergie, mésons et baryons (protons et neutrons).
Je termine ma liste sur l’atome hypernucléaire, mais j’espère que ça vous a montré un peu l’ampleur des possibilités offertes par la physique des particules. Alors que le tableau périodique permet de voir tout le « bestiaire » de la chimie, le noyau de l’atome est à lui seul un autre monde rempli de quarks, qu’il est possible d’assembler en mésons, hypérons et d’autres particules et atomes exotiques. C’est un peu ce qu’ils font au Cern dans le LHC et dans les autres accélérateurs de particules dans le monde.
L’astéroïde 243 Ida et sa lune, Nasa.
Alors que d’un côté certains éléments extraits de la Terre deviennent de plus en plus rares, et que de l’autre on a des astéroïdes qui sont plein d’éléments rares, il est logique désormais qu’on en arrive à des projets de minage des astéroïdes, y compris par des sociétés du secteur privée (Planetary Ressources, DSI…).
Mais une question peut être posée : pourquoi les astéroïdes sont remplis d’or ?
Déjà, les astéroïdes contiennent de l’or et d’autres éléments. Ils ne sont pas fait uniquement de ça. Mais pour savoir pourquoi il y en a plus que sur Terre, il faut commencer par le début : d’où vient l’or ?
La formation de l’or dans l’univers
Déjà il faut savoir un truc : dans l’univers, 92% des atomes sont de l’hydrogène. La majorité des 8% d’atomes qui restent sont de l’hélium.
Tous les éléments autres que ces deux là sont seulement là à l’état de traces.
Si on a des planètes entières formées de ces éléments, c’est que les planètes représentent une masse ridicule, même face à une étoile de taille moyenne : les 4 planètes telluriques réunies représentent ~0,000007% de la masse du Soleil.
On peut donc considérer que toute la masse des planètes rocheuses ne représente qu’une trace dans le système solaire.
Parmi les éléments autres que l’hydrogène et l’hélium, on distingue deux catégories : les éléments légers (avant le fer dans le tableau périodique) et les éléments lourds (après le fer dans le tableau périodique).
Les éléments légers sont produits dans les étoiles, par fusion nucléaire (c’est le cas de l’oxygène, de l’argon, du carbone, du calcium…) et les éléments plus lourds sont produits lors des supernovas, l’explosion des étoiles massives (le cas du cuivre, or, uranium, platine, tungstène…).
C’est donc des supernova que provient le métal qui nous intéresse : l’or.
La présence d’or sur Terre
Après une supernova et la mort d’une étoile géante, tous les éléments se retrouvent diffusées dans l’espace. La matière (toujours majoritairement de l’hydrogène), sous l’effet de la gravité va de nouveau se condenser et une nouvelle génération d’étoiles va se former, avec autour d’elles une série de planètes composées des éléments plus lourds qui n’ont pas eu le temps de tomber dans la nouvelle étoile.
La majorité de l’or sur Terre provient de là… Mais pas celui de vos bijoux !
Notre planète, juste après sa formation, était une boule de magma liquide : les éléments ont peu à peu décantés, et les éléments les plus lourds se sont retrouvés au centre et les plus légers sont restés en surface : on appelle ça la différenciation planétaire.
Parmi les constituants du noyau terrestre, on trouve donc du fer et du nickel, mais aussi de l’or, du platine, du rhodium, du tungstène… La croûte terrestre est composée majoritairement de silicium, d’oxygène, d’aluminium, de titane.
Il y a beaucoup d’or sur Terre : c’est juste qu’elle se trouve dans le noyau.
Alors d’où vient l’or des filons et des mines ?
Il vient en fait des astéroïdes. En effet, ces derniers, bien moins massifs et beaucoup moins chaud, n’ont pas eu de différenciation : tous les éléments chimiques y sont donc plus ou moins mélangés.
Quand un astéroïde frappe la Terre, ses constituants se déposent à la surface de la planète. Il suffit qu’un astéroïde soit tombé assez récemment pour que son contenu soit encore directement accessible à la surface. La matière des météorites tombés plus anciennement remonte quant-à-elle à la surface grâce au volcanisme.
Quand on exploite une mine d’or (ou de n’importe quel métal lourd et particulièrement ceux qui sont inertes chimiquement), on exploite généralement soit les abords d’un ancien site météoritique, soit une région anciennement volcanique. C’est ça qui fait que le minerai est présent sous la forme de filons et non pas de façon uniforme partout sur Terre.
L’or dans les astéroïdes
Je l’ai dit un peu plus haut : les astéroïdes, comme toutes les planètes rocheuses sont formés des restes d’éléments lourds et solides présents sur place lors de la formation du système solaire. L’or n’y est pas plus abondant que sur Terre : l’or y est plus abondant que dans la croûte terrestre seulement. De plus, l’or s’y trouve aussi bien à la surface qu’à l’intérieur, à cause de la différenciation qui n’a pas eu lieu.
C’est parce qu’elle se trouve à la surface qu’il est beaucoup plus rentable et pratique d’aller la chercher là-bas ! En effet, envoyer une sonde spatiale sur un astéroïde, on sait le faire et c’est seulement un problème de coût. Par contre, creuser un trou jusqu’au centre de la Terre, on ne sait pas faire et ce n’est pas possible techniquement (il faut traverser le manteau rocheux à 5000 °C puis creuser dans un noyau métallique, le tout sous des pressions et des contraintes inimaginables).
Voilà pourquoi on parle (souvent de façon hyperbolique quand même) d’astéroïdes « remplis d’or » : l’or y est simplement plus accessible que sur Terre et pas forcément en quantité plus importantes.
Pour aller plus loin, sachez que tous les trésors ou ressources minières qu’il est envisagé de miner ne sont pas d’or ou d’argent : certaines comètes sont remplies de glace d’eau. Or l’eau, si on l’électrolyse, on se retrouve avec de l’hydrogène et de l’oxygène, qui n’est autre que du carburant pour fusée. Il est dès lors possible de faire des « stations essence » pour les expéditions spatiales : ce serait beaucoup plus rentable là aussi que de prendre le carburant sur Terre (qui y est plus abondant, mais qui pèse lourd au décollage).
Sans oublier non plus l’énergie solaire : sur Terre, une bonne partie du flux lumineux reçu du Soleil est directement réfléchie dans l’espace et une autre partie est diffusée ou absorbée par l’atmosphère. L’espace est encore plus propice à l’exploitation de l’énergie solaire qu’elle ne l’est sur Terre : ce n’est pas pour rien que la station spatiale internationale (ISS), le télescope spatial Hubble ou diverses autres sondes ou satellites sont alimentées par des l’énergie solaire.
Enfin, d’autres éléments chimiques sont simplement absents de la croûte terrestre car ils se sont envolés dans l’espace inter-planétaire. C’est le cas de l’hélium-3. À cause du volcanisme et de la modification des roches continentales, tout l’hélium-3 que la Terre avait n’est plus là aujourd’hui. La Lune en revanche possède d’importantes ressources d’hélium-3, piégée dans la roche depuis des milliards d’années. Cet hélium est un possible combustible nucléaire pour des centrales à fusion, qui sont beaucoup plus propres que les centrales actuelles. L’hélium-3 et la Lune sont à la base de l’intrigue du film « Moon ».
Contrairement à ce que peut laisser penser le titre, Noël n’est pas une fête extraterrestre : j’entends par astronomique qu’il tire son origine de l’observation des astres.
Vous l’avez sûrement remarqué, en hiver la journée est courte et la nuit est longue, alors qu’en été la journée est longue et la nuit courte.
Le passage des saisons montre donc une alternance entre une période, du 21 juin au 21 décembre, où la journée dure de moins en moins longtemps et où le Soleil est de plus en plus bas dans le ciel. et une autre période, du 21 décembre au 21 juin, où la journée est de plus en plus longue et le Soleil va de plus en plus haut dans le ciel.
Nos ancêtres l’avaient également remarqué. Or comme le Soleil était essentiel à leur vie et à leur survie, ne serait-ce que pour faire pousser les récoltes et pour éclairer. Ils étaient donc naturellement inquiet que le Soleil descende si bas dans le ciel hivernal. Quand finalement vint le moment où le Soleil s’arrête de descendre le jour du solstice d’hiver (de « sol », Soleil et « -stice », arrêt) pour ensuite commencer à se relever, les Païens organisaient alors une grande fête, le « Sol Invictus » destinée à célébrer le présage de jours plus longs et plus chauds.
L’idée du Soleil renaissant dans sa splendeur a donné l’expression « dies natalis solis invicti », ou le jour de la naissance du Soleil invaincu.
Le solstice d’hiver ayant généralement lieu autour du 21 décembre, la fête se tient le 24 ou le 25 décembre, soit quelque jours après le solstice, le temps que sa remontée dans le ciel soit notable et visible par les observateurs et les astronomes.
Quant à la définition chrétienne de Noël, elle a été placée le même jour que la fête Païenne par l’Église, afin de profiter d’une fête qui était déjà largement implantée dans la culture populaire et ainsi mieux se propager un peu partout en Europe. Il a quand même fallu attendre l’an 336, soit plus de trois siècles après Jésus Christ, pour que la naissance de ce dernier soit placée le 25 décembre et vienne remplacer Sol Invictus. Car bien avant l’an 336, et même avant l’an 1, Sol Invictus et toute cette période était déjà festive pour beaucoup : les Romains, les Grecs et les Gaulois célébraient entre autres :
Sol Invictus, et le retour des jours plus longs ;
le Culte de Mithra, chez les Romains ;
les Saturnales, chez les Romains, pour fêter le dieu Saturne ;
Épona, une déesse Gauloise, également fêtée en décembre ;
Les Petites Dionysies (rurales), à la même époque de l’année chez les Grecs et célébrant Dionysos. Les Grandes Dionysies, dans les villes, avaient elles lieue en mars.
Durant la fin du mois de décembre les anciens organisaient donc des festins et s’échangeaient des cadeaux. Les esclaves et les maîtres étaient temporairement égaux voire leurs statuts échangés, les écoles et le travail suspendus.
Tous ces rituels très populaires ont été plus ou moins conservés par l’Église dans ce qui deviendra après le IIe et IIIe siècle, le Noël chrétien.
Voilà : ce que l’on fête le 25 décembre comporte donc à l’origine et avant tout une dimension astronomique et sociale.
Donc si la dimension religieuse de Noël vous gêne ou vous semble anti-laïque, vous pouvez toujours fêter le même jour de l’année pour son côté astronomique. Sinon, vous pouvez également fêter l’anniversaire d’Isaac Newton (le 25 décembre 1642 dans le calendrier Julien, en vigueur à l’époque en Angleterre) , ou « Newtonmas ». Et pour le nouvel an, fêtez donc la périhélie le 4 janvier ! Le jour de l’an actuel est placé 7 jours après Noël par l’église, mais le 4 janvier marque, lui, la date où la Terre sur son orbite elliptique est au plus proche du Soleil.
En ce Jour de l’An, on vous a probablement souhaité la bonne année un gogool de fois, mais je vous la souhaite ici une fois de plus quand même : bonne année à tout le monde !
Mais au fait, savez-vous vraiment ce qu’est une année ?
La durée de révolution de la Terre autour du Soleil ? Oui, mais comment ? Car la Terre ne passe pas toujours au même moment au même endroit ni au même endroit. Voyons tout ça.
On distingue plusieurs années : l’année civile, l’année solaire, l’année sidérale et l’année anomalistique (oui, ça devient de plus en plus compliqué, aussi je vais m’arrêter ici, car il y en a d’autres, comme l’année sothiaque, en référence à l’étoile Sirius ; draconitique, qui fait intervenir l’orbite de la Lune ou l’année scolaire qui n’a rien à voir).
L’année civile
C’est l’année des calendriers, qui commence le 1er janvier et se termine le 31 décembre.
(image) Elle compte un nombre entier de jours, et ceci est important car du point de vu de la rotation et la révolution des astres, rien n’oblige la révolution d’être d’une durée égale à un nombre entier de rotations. Cette particularité est donc purement artificielle et mise là par simple commodité. Si l’année civile autorisait des fractions de jours, alors elle durerait 365 jours 5 heures 49 minutes et 12 secondes.
2016 sera une année bissextile, donc à 366 jours : le jour de plus que les autres années compensant la fraction d’année accumulée au cours des 4 dernières années.
Une année sur quatre est bissextile, sauf quand l’année est celui d’un nouveau siècle : les années 1700, 1800 ou 1900 n’étaient pas bissextiles. Mais quand l’année d’un nouveau siècle est un multiple de 400, alors il redevient bissextile : l’année 1600 était bissextile et l’an 2000 aussi.
Cette algorithme un peu étrange se comprend quand on remarque qu’une année vaut $365\text{ jours} + \frac{1}{4}\text{ jour} − \frac{1}{100}\text{ jour} + \frac{1}{400}\text{ jour}$
L’année solaire (ou année tropique)
Elle rend compte des saisons et de la position du Soleil dans le ciel : par exemple, une année solaire sépare exactement deux équinoxes de printemps, ou exactement deux solstices d’été.
L’année solaire est estimée (en 2000) à 365 jours 5 heures 48 minutes 45,25 secondes. C’est donc légèrement moins que l’année civile.
La raison à l’existence de cette année est que l’axe de rotation de la Terre oscille, comme, une toupie sur le point de s’arrêter. On appelle ça la précession, et on parle ici de la précession des équinoxes :
La précession des équinoxes : l’axe de rotation de la Terre oscille. (image)
Le cycle de la précession des équinoxes pour la Terre est de 26 000 ans environ. Une autre conséquence de cette précession, en dehors de la durée de l’année solaire, est que le pôle nord géographique ne pointera pas toujours au même endroit dans le ciel. Actuellement pointant vers l’étoile polaire, d’ici quelques milliers d’années ça ne sera plus le cas. L’étoile la plus proche du nord en l’an 3 100 et jusqu’à l’an 5 300 sera γ Cephei.
L’année sidérale
Cette définition de l’année rend compte de la position du Soleil dans le ciel, sur le fond composé des autres étoiles. En effet, au cours de l’année, les constellations (et donc les étoiles) visibles dans le ciel à une heure donnée changent. Quand on retrouve les mêmes constellations (et donc les mêmes étoiles) au même endroit dans le ciel et à la même heure, alors il s’est passé une année sidérale.
Cette année là est encore différente en durée : elle dure (pour l’an 2000), 365 jours 6 heures 9 minutes 10 secondes (soit 20 minutes de plus de l’année tropique). La différence ici n’est issue que de sa définition : l’année tropique ne considère que la position du Soleil dans le ciel, alors que l’année sidérale (du latin « sider », étoiles) prend en compte les autres étoiles visibles, et il se trouve qu’à cause de la précession des équinoxes — là encore — il faut attendre quelques minutes de plus, pour que le Soleil rattrape la position des autres étoiles décalées à cause de la précession des équinoxes.
L’année anomalistique
Il s’agit de la durée entre deux passages de la Terre à la périhélie. L’orbite de la Terre étant une ellipse et pas un cercle parfait, il y a un point de l’orbite où la Terre est au plus proche du Soleil (le périhélie) et un point où il est au plus loin (aphélie).
Or l’orbite elliptique de la Terre est elle-même en rotation autour du Soleil : l’ellipse change d’orientation au fil des années, notamment à cause de l’influence gravitationnelle des autres planètes proches (Vénus) ou très massives (Jupiter) :
La précession du périhélie : l’orbite de la Terre se décale tous les ans). (image)
Il faut environ 112 000 ans pour que l’orbite ait ainsi fait un tour complet.
L’année anomalistique dure 365 jours 6 h 13 min et 52,539 secondes, légèrement plus longue que l’année sidérale donc, le temps que la Terre rattrape le point de périgée qui s’est décalé (dans le même sens que la Terre) durant l’année écoulée.
↑ Paysage en Islande, île formée grâce à la tectonique des plaques (source)
La Relativité Générale a 100 ans depuis quelques semaines. La physique quantique — celle qui permet les ordinateurs, les lasers et les Led — est à peine plus ancienne : les prémisses de cette théories ont été posées par Bohr en 1900.
On peut penser que ces deux grands modèles théoriques de la physique sont les seules chamboulements qui ont eu lieu en science au cours du siècle dernier. Et bien sachez que c’est faux : d’autres faits marquants qui nous semblent parfaitement acquis sont en réalité bien plus récents que ces deux là !
Dans cet article, remettons à leur place quelques dates qui ont marqué les sciences et constatons que tout ce qu’on apprends à l’école aujourd’hui est en réalité très récent !
L’âge de la Terre
Beaucoup de tentatives de détermination de l’âge de la Terre ont eu lieu : Ussher et Newton au XVIIe siècle dataient la naissance de la Terre à 4000 ans avant J.-C en se basant sur la bible. Les scientifiques Lamarck et Maillet au XVIIIe siècle avaient calculé que la Terre devait avoir entre 2 et 4 milliards d’années, d’après les couches géologiques et les courants océaniques. Kelvin, lui, donnait environ 100 millions d’années à notre planète, utilisant la récente discipline de la thermodynamique à laquelle il a lui-même grandement contribué.
La mesure de l’âge de la Terre à sa valeur admise aujourd’hui — 4,55 milliards d'années — est basée sur la datation radioactive de l’uranium sur des météorites. Cette valeur a été déterminée seulement en 1953 et est due à Clair Patterson. C’est la méthode la plus fiable pour déterminer l’âge de notre planète et celle du système solaire : utiliser les couches géologiques ne l’est pas car les premières couches ont été détruites la tectonique des plaques, et les courants océaniques actuels n’ont quant à eux pas toujours existé non plus.
En parlant de l’idée de la tectonique des plaques, celle-ci est également très récente.
La tectonique des plaques
Comment expliquer les formes complémentaires de l’Amérique du sud et de l’Afrique ? Et comment expliquer les similitudes géologiques de ces deux régions, et la découverte des mêmes fossiles de part et d’autre de l’atlantique ? Pour Wegener en 1915, c’était dû à la dérive des continents. Cette idée a longtemps été rejetée, faute de preuves (à l’époque on se contentait de dire qu’un « pont » naturel entre l’Afrique et l’Europe reliait l’Amérique, et que ce pont à disparu depuis).
Ce n’est qu’en 1960, après avoir cartographié les fonds de l’océan Atlantique, que Bruce Heezen et Marie Tharp ont découvert une preuve de l’expansion des océans et de la dérive des continents : la présence des rifts océaniques, où naissent le fond des océans. Deux années plus tard, Hess montra comment fonctionne le phénomène inverse : la subduction.
Il a fallu attendre 1967 pour voir apparaître une théorie complète sur des plaques continentales indépendantes les unes des autres. L’intuition d’une tectonique des plaques a donc à peine 100 ans et la théorie et les preuves qui vont avec, à peine moitié moins.
L’âge du Soleil et son fonctionnement
Le Soleil a le même âge que la Terre et que le reste du système solaire. Son fonctionnement n’est pourtant connu que depuis récemment. La cause ? La fusion nucléaire et la radioactivité qui n’étaient pas connus avant le début des années 1900 ! Les seules idées avant cela pour décrire son fonctionnement étaient la chimie : on pensait que le Soleil était fait de charbon et qu’il brûlait.
On sait aujourd’hui que ce modèle donnait à notre étoile qu’une espérance de vie de seulement quelques milliers d’années (ce qui était à l’époque conforme à la bible et donc plus ou moins accepté).
En 1860, Kelvin proposait un mécanisme de compression et décompression du Soleil pour expliquer la chaleur émise. Ce mécanisme connu sous le nom de mécanisme de Kelvin-Helmholtz donnait au Soleil un âge de 20 millions d’années.
Il a fallu attendre 1920 avec Perrin pour que l’hypothèse de la fusion nucléaire stellaire fasse son apparition, et plus longtemps encore pour expliquer son spectre d’émission (Payne en 1925), sa formation (Chandrasekhar en 1939) et la présence détectée de tous les métaux et éléments lourds dans le Soleil ainsi que la formation des systèmes planétaires (Burbidge & Co en 1957).
Pensez-y : on utilise les métaux depuis l’antiquité et la chimie moderne depuis plus de 250 ans. Mais avant 1957, la seule réponse possible à la question sur l’origine de ces métaux était « on les extrait du sol, dans les mines. », sans pouvoir expliquer comment ils se sont retrouvés dans le sol… Il a fallu attendre l’astrophysique moderne pour expliquer l’origine des atomes qui composent les objets, notre planète et même notre propre corps.
Les dinosaures
Les os de dinosaures sont connus depuis toujours. Les civilisations antiques les attribuaient à des restes de créatures mythologiques (dragons…). Il a fallu attendre le XIXe siècle et le début du classement des espèces vivantes selon leur caractéristiques pour que les dinosaures soient classés comme d’anciennes espèces de reptiles, aujourd’hui éteints. Leur âge n’était pas connu avec certitude (pour la simple raison que l’âge de la terre n’était pas connu non plus).
Le terme « dinosaure » a lui-même été inventé en 1842, par un paléontologue du nom de Richard Owen.
De plus, ce que l’on considère nous même comme des lézards géants recouverts d’écailles pourrait bien être un faux aperçu des dinosaures : de plus en plus, on pense qu’ils étaient recouverts de plumes ou de poils très colorés…
L’expansion de l’Univers & le Big-bang
Avant la publication de la théorie de la relativité par Einstein, l’idée d’un univers en expansion n’était pas du tout acceptée.
Depuis Newton, on se contentait d’un univers fixe, qui était toujours là et qui le sera toujours également. La raison était simple : un univers fixe était suffisant pour expliquer tout ce qu’on voyait. Il n’y avait pas besoin d’une complication supplémentaire dans les théories cosmologiques qui l’étaient déjà suffisamment.
En 1920, Lemaître montra que la relativité générale autorisait le fait que l’univers ne soit pas statique : qu’il puisse être en expansion, en contraction et qu’il puisse évoluer. En 1929, Hubble (le gars, pas le télescope) découvrit que les galaxies lointaines s’éloignaient tous de nous, notant au passage que la vitesse d’éloignement augmentait avec leur distance par rapport à nous.
La conclusion à ça est que l’univers était en expansion. Ceci signifiait aussi qu’à chaque instant dans le passé, l’univers était plus petit qu’il ne l’est dans le présent, et donc qu’à un moment, l’univers était aussi petit qu’un point. Ce point aurait soudainement explosé, créant la matière, l’énergie, l’espace-temps et évoluant en tout ce qu’on observe aujourd’hui. Cette explosion ponctuelle, c’est le Big-bang.
L’idée d’un Big-bang apparut seulement dans les années 1930, et le terme lui-même n’était pas né avant 1949.
L’accélération de l’expansion de l’Univers
Si l’univers est en expansion, on imaginait 3 cas possibles : dans la première, l’expansion est infinie, la force de gravité n’étant pas suffisante pour l’arrêter ; pour la seconde, l’expansion va un jour s’arrêter et s’inverser : on aura alors droit à une contraction de l’univers ; et enfin la troisième, l’expansion est infinie mais va tendre asymptotiquement vers un état d’équilibre, où plus rien ne bouge : les forces de gravité et les forces de répulsion du Big-bang étant parfaitement équilibrées.
Les mesures effectuées (par des groupes de recherches différents et opposés, qui plus est) pour connaître la vitesse et l’évolution de la vitesse de l’expansion a donné un résultat totalement inattendu mais identique pour chaque groupe de recherche : l’expansion est accélérée ! Ce n’a pas 20 ans, puisqu’elle date de 1998.
Aucun théorie n’explique encore cette accélération : pour le moment on donne le nom d’Énergie noire à quoi que ce soit qui puisse être responsable de ce phénomène.
Les particules subatomiques
Électron, proton, neutrons… ça vous dit quelque chose ?
Le modèle de l’atome date du début du XXe siècle et l’idée d’une matière composée de particules, bien que proposée depuis la Grèce antique, était largement débattu jusqu’au début du XXe siècle.
L’électron et le proton sont respectivement mis en évidence en 1897 et 1919. Pour le neutron, il faut attendre Chadwick en 1932… À peine 4 ans après que le physicien Max Born déclara « la physique, telle que nous la connaissons, sera terminée dans 6 mois », rejoignant Kelvin en 1900, disant que la physique était une science sans avenir, quelques années avant la naissance de la physique quantique et de la relativité.
Le classement phylogénétique
Il s’agit de la taxinomie : le classement et le répertoriage des espèces vivantes. Le classement phylogénétique remplace la classification dite classique. Cette dernière se base sur les ressemblances visibles entre les espèces, alors que le classement phylogénétique ne se base pas uniquement sur le visuelles, mais aussi sur des choses qui le sont beaucoup moins, comme des membres ou des organes atrophiés par l’évolution. La classification classique aurait ainsi classé les dauphins parmi les poissons, alors qu’on sait qu’il est en réalité plus proches de l’humain que du saumon.
La classification phylogénétique moderne date de 1950, quand Willi Hennig en a posé les fondements.
L’ADN
Si l’ADN — ou acide désoxyribonucléique — en tant que molécule a été identifiée et isolée en 1869 par Miescher, son rôle dans la génétique n’a été démontré qu’en 1952 par Hershey et Chase. L’idée de l’existence de gènes définissant les caractères phylogénétiques des espèces vivantes n’a été présentée, elle, qu’en 1913 par Mendel, et elle expliquait alors le principe de l’évolution de Darwin publié en 1858 et l’hérédité des caractères, idée qui n’avait à l’époque aucune base solide pour être acceptée ou acceptable.
La structure en double-hélice de l’ADN est plus récent de quarante ans : c’est en 1952 que celle-ci a été découverte et photographiée par radiographie à rayons X par Rosalind Franklin et publié un an plus tard par Watson et Crick.
—
Cette liste montre à peu près que rien ne doit être pris pour acquis : une grande partie du monde actuel repose sur des découvertes qui ne datent que du siècle dernier : bio-ingéniérie, informatique, exploration spatiale, qui ont tous eu des effets de bords qu’on retrouve dans la vie courante aujourd’hui : la découverte de la quantique permet l’informatique ; celle de la relativité permet le GPS ; la construction du LHC permet le Web ; la découverte de l’âge de la Terre a permis de sauver des millions de personnes du plomb ; la conquête spatiale autorise l’imagerie satellite et la prédiction des cyclones ou de sauver des vies…
Qui sait quelles seront les découvertes scientifiques majeures du XXIe siècle ? Le boson de Higgs en est déjà une. Il y aura probablement des applications aussi.
Et concernant notre ignorance avant ces découvertes, je citerais Carl Sagan :
Avec un peu de chance nos descendants auront pour notre ignorance actuelle la même indulgence que nous à l’égard des Anciens qui ne savaient pas que la Terre tournait autour du Soleil.
Dans cet article, je vous montrer qu’il faut parfois se méfier de l’eau qui dort, même en sciences !
Parmi les exemple de phénomènes curieux qui peuvent être interprétés de façon incorrecte se trouve le thermomètre de Galilée.
Un thermomètre de Galilée (image)
Ce thermomètre, inventé par Galilée il y a 350 ans se présente comme un tube fermé rempli de liquide et dans lequel flottent des ampoules scellées, elles aussi remplies en partie de liquide (coloré pour la décoration).
Le fonctionnement repose sur un équilibre entre la densité des fluides et celle des ampoules, et qui est déplacé en fonction de la température.
Mais contrairement à ce que ceci peut laisser entendre ou ce que l’observation du thermomètre peut laisser penser, la densité des ampoules ne varie pas : le liquide dans les ampoules change de pression et de température, mais le volume et la masse des ampoules ne changent pas, elle : la densité des ampoules reste donc constante.
C’est la densité du fluide transparent qui varie partout autour : quand la température monte, ce fluide se détend et sa densité diminue : quand cette densité atteint celle d’une ampoule et passe en dessous, l’ampoule, baignant alors dans un liquide devenu moins dense qu’elle, se met à couler.
Vu que la température est indiquée sur la l’ampoule, il suffit de la lire pour connaître la température ambiante.
Alors certes, le thermomètre est lui aussi scellé, mais le haut du tube principal n’est pas rempli de liquide : il est rempli d’air (ou un autre gaz) : grâce à cela, le liquide peut se détendre dans le gaz (qui se comprime) sans que le thermomètre en lui-même ne se déforme.
Lors de la fabrication de ces thermomètres, la densité des thermomètres doit être calibrée de façon très précise par rapport au liquide principal du thermomètre. Si le liquide principal est de l’eau, la densité varie assez peu avec la température : entre 20 °C et 21 °C, la densité de l’eau ne diminue que de 0,021 %. Entre 20 °C et 90 °C, la différence de densité n’est que de 3 %.
Pour résumer donc : ce n’est donc pas parce que ce sont les ampoules qui montent et qui descendent, que c’est là que se passe toute la science. Il faut parfois voir plus large, plus grand que juste ce qui attire notre attention ;-).
Les batteries, piles et accumulateurs sont à peu près partout, mais savez-vous comment ça marche ?
Si on prend comme exemple l’accumulateur qui se trouve dans votre téléphone ou votre ordinateur portable, il y a de grandes chances qu’il s’agisse d’une batterie Li-Ion.
Dans cette dénomination :
Li est symbole du lithium, un élément chimique en haut à gauche sur le tableau périodique, de la famille des métaux.
Un ion est simplement un atome qui se retrouve avec un électron en plus ou en moins par rapport à la normale.
Les batteries (plus précisément des accumulateur) au Li-Ion contiennent donc des ion de lithium.
Voyons désormais comment faire de l’électricité avec du lithium.
Déjà, c’est quoi l’électricité ?
Prenons l’électricité statique : quand vous prenez un coup de jus, par exemple après avoir frotté un bout de nylon sur de la laine, ce sont en fait des électrons accumulés sur le nylon qui sautent sur votre main, créant ainsi un courant électrique très bref mais suffisant pour vous secouer. En le frottant, le nylon arrache des électrons à la laine et il se forme un déséquilibre électrique (on parle d’une différence de charge) : votre main sur le nylon va alors capter ces électrons.
Dans le cas de l’électricité statique, on a séparé des électrons pour produire de l’électricité : le courant apparaît quand les électrons reviennent à leur emplacement initial.
On pourrait alimenter un smartphone avec une grosse pelote de laine et une énorme toile de nylon, mais ce ne serait pas pratique. On a trouvé mieux : la chimie.
Certaines réactions chimiques, que vous connaissez tous, transforment du carbone et de l’oxygène en dioxyde de carbone :
$$\text{C} + \text{O}_2 → \text{CO}_2$$
Il existe des réactions chimiques qui libèrent des électrons : on les nomme réaction d’oxydation. D’autres réactions chimiques ne peuvent avoir lieu que si on leur fournit des électrons : ce sont des réactions de réduction. Dans ces réactions là, l’électron est respectivement un produit et un réactif. L’électron tout seul fait donc partie de de l’équation de réaction chimique.
C’est exactement ce genre de réactions qui se produisent dans votre batterie : à une borne a lieu une réaction chimique qui libère un électron : cet électron va traverser tout le circuit électrique et alimenter une lampe, un écran ou un haut parleur, puis va finir sur l’autre borne où il va être consommé par la seconde réaction.
Si les deux réactions (oxydation et réductions) se font de façon combinée, comme dans le cas d’une batterie, on parle d’une réaction d’oxydo-réduction.
Dans ce cas d’une batterie au Li-Ion, c’est le lithium qui va tantôt libérer un électron et tantôt en absorber un.
La réaction d’oxydation, sur la borne négative et qui libère un électron est :
Ici, le $C_6$ représente du graphite (du carbone) qui piège le lithium. Le $Li_nCoO_2$ représente une matrice métallique (à base d’oxyde de cobalt lithié).
Même une fois chargée complètement, il reste un peu de lithium dans la matrice de cobalt : si tout le lithium venait à sortir de l’oxyde de cobalt, la batterie serait morte car cet oxyde de cobalt ne permettrait plus d’accueillir à nouveau des ions lithium : il lui fait un peu de lithium initialement (d’où la présente du $x$ et du $n$ un peu étranges, dans les équations).
En temps normal ces réactions chimiques se font toutes seules, mais dans une batterie on a séparé le graphite et la matrice en oxyde de cobalt lithié pour que la réaction complète ne puisse se faire que si on relie les deux bornes de la pile par un circuit électrique. En effet, le circuit électrique est alors le seul moyen pour les électrons de la réaction de participer à la réaction.
C’est aussi la raison pour laquelle il ne faut pas ouvrir une batterie au lithium : en faisant ça, on risque de mettre en contact tous ces produits et d’amorcer la réaction, qui est très calorique (exothermique) et qui risque de faire exploser la batterie violemment.
Lors de la recharge de la batterie au lithium, le courant électrique du chargeur force la réaction chimique à se faire dans l’autre sens : on remet donc les électrons et le lithium à leur place initiale, de façon à ce que si on branche à nouveau un circuit électrique, la batterie puisse de nouveau l’alimenter.
Ceci est bien-sûr possible parce que ces réactions chimiques sont réversibles sous l’effet d’une tension électrique (celle du chargeur). Ce n’est pas le cas de toutes les réactions chimiques et ça explique donc pourquoi une pile alcaline ou saline ne peut pas être rechargé mais que d’autres technologies de piles puissent l’être : lithium-ion, lithium-polymère, nickel-cadmium…
L’un des plus grands mystères actuel de la physique concerne l‘accélération de l’expansion de l’univers et la chose qui en est responsable : l’énergie noire.
L’univers est en effet en expansion, comme l’a montré Edwin Hubble en 1929. Cette expansion, en plus d’être là, s’effectue — contre toute attente — de plus en plus vite : elle accélère. Ce phénomène a été découvert en 1998 seulement.
L’origine ce cette expansion n’est pas connue, mais elle pourrait avoir quelque chose à faire avec la pression négative du vide…
La physique quantique est une des théorie les plus solides qui soit : elle n’a encore jamais été invalidée. Tout ce qu’elle prédit et aussi bizarre que ces choses peuvent être à prime abord, a pu être vérifié : effet tunnel, téléportation quantique, intrication…
Pourtant, quand on essaye de l’utiliser pour expliquer l’énergie noire, on trouve une erreur gigantesque d’un facteur $10^{120}$, soit l’une des plus grandes erreurs entre théorie et expérimentation jamais observée en sciences.
Tout ça pour quoi ?
Juste pour dire que même nos théories les plus puissantes dont la physique dispose aujourd’hui se cassent les dents de façon monumentale quand on essaye d’expliquer un phénomène tel que l’énergie noire qui compte pour les trois-quarts de ce qui se passe dans l’univers.
On est donc très loin de tout connaître de la mécanique de l’univers. En fait, toute la physique actuelle (gravité, quantique, relativité, électromagnétisme, thermodynamique…) n’explique des choses que dans le domaine de la matière baryonique (la matière « normale », celle du tableau périodique), qui ne représente qu’un petit 4% dans la masse de l’univers (le reste étant à trois quarts d’énergie noire et pour un quart de matière noire.
Toute notre science actuelle n’explique donc qu’une fraction encore plus petite de ce 4% de l’univers.
À la question « que reste-t-il à faire en sciences ? » je répondrait donc : « pratiquement tout. ».
Pourtant se poser la question « que reste-il à faire en science ? » n’est pas une mauvaise question. L’un des plus noms les plus illustres de la science, à savoir Lord Kelvin, disait un jour de l’année 1900 qu’il n’y avait plus rien à faire en science ; que c’était une filière vouée à être délaissée.
Cinq ans plus tard, Einstein proposa la Relativité, puis la Quantique, les deux théories majeures du XXe siècle, qui expliquaient simplement tout ce que la physique connue de Kelvin n’expliquait pas.
Kelvin a fait une grosse bourde ce jour là, oui. Mais ne faisons pas la même.
Oui, le boson de Higgs est découvert (à 99,99% de certitude), mais de nouvelles questions sont apparues : le Higgs n’était pas tout à fait tel qu’on l’avait prédit (des écarts dignes d’intérêt ont pu être observés). Et c’est sans compter que la « particule de Dieu » n’a jamais eu pour but d’expliquer tout ce qui restait à expliquer. Ce n’est qu’un petit élément du puzzle : elle n’explique même pas le fonctionnement de la gravitation (alors les trois autres forces de la nature sont expliquées).
Si on veut continuer de découvrir d’où on vient et ou on va et au passage cueillir toutes les inventions géniales produites par la recherche fondamentale (le Web, les micro-ondes, les IRM, le Kevlar, les couvertures de survie…), la recherche scientifique doit se poursuivre.
Même si le film Lucy prétend le contraire, c’est un mythe que de penser que le cerveau n’utilise que 10% de ses capacités. Et même si c’était vrai, faire passer ces 10% à 100% ne donnerait a priori pas de pouvoir sur la matière et le temps (comme dans le film), il rendrait simplement plus intelligent.
Parallèlement, on entend que le cerveau humain est le plus puissant ordinateur qui soit. Ceci est un peu trompeur aussi car on ne peut pas vraiment comparer : une machine n’est pas « intelligente », car elle n’est pas douée d’une réflexion. Elle sait seulement effectuer des milliards d’opérations de calcul par seconde.
À l’inverse, il pourrait être amusant de voir quel ordinateur il faudrait monter pour atteindre la capacité d’un cerveau, d’un point de vue purement technique. C’est ce que je fais ici, en croisant les sources.
La mémoire
Des serveurs (source)
Dans un ordinateur, on distingue la mémoire vive et la mémoire morte. On peut aussi ajouter la mémoire de masse.
Si on veut transposer ça à un être vivant, je dirais que l’ADN constitue notre mémoire morte : c’est elle qui dit comment nous fonctionnons. L’ADN c’est un peu le bios à nous. Tout comme la mémoire morte est programmée à la construction d’un ordinateur et par définition non reprogrammable, l’ADN c’est pareil : ce sont nos parents qui la composent lors de notre conception.
La capacité de la mémoire morte correspondant à l’ADN est de l’ordre de 455 millions de téraoctets par gramme d'ADN (source).
La mémoire de masse (disque dur, clé USB, CD…), c’est ce que l’ordinateur enregistre en grande quantité pour plus tard. Si l’ordinateur est détruit, la mémoire de masse perdure de façon indépendante. Pour un humain, ça correspondrait alors à tout ce que nous écrivons ou produisons : livres, poèmes, récits, cahiers, photos imprimées, films, cassettes, peintures, musique, etc. Tout ceci perdure même après notre mort, et peut être transféré à nos descendants.
Il n’y a pas de limites au nombre de clé USB qu’un ordinateur peut remplir de données, et il n’y a pas non plus de limite quant au nombre de livres qu’un humain peut écrire.
Il reste alors la mémoire vive. C’est elle qui correspond à la mémoire de notre cerveau. Les deux sont similaires dans le sens où elles sont vidées quand on met l’ordinateur hors tension : le cerveau est vidé de ses souvenirs quand on meurt. De plus, les informations ne sont pas (encore ?) transférables sans passer par la mémoire de masse (écrits, films) ou par une communication induite par le cerveau (paroles, signes de la main).
La mémoire vive permet de stocker ce sur quoi l’ordinateur est en train de travailler avant de les mettre sur une mémoire de masse. Il inclut aussi les données et les programmes en cours d’exécution.
Le cerveau utilise sa mémoire pour stocker les souvenirs et les « programmes » : comment marcher ? comment cuisiner ? comment conduire ? comment parler ?
Selon les sources, la mémoire humaine serait de 2,5 Po (2,5 pétaoctets) soit 2 500 téraoctets. C’est assez considérable, mais il est aujourd’hui tout à fait envisageable de remplir une pièce avec des ordinateurs de façon à atteindre cette capacité de stockage : les disques durs de plusieurs dizaines de téraoctets existent actuellement, et il suffirait de seulement quelques centaines d’ordinateurs pour atteindre la capacité du cerveau (quelques baies de serveurs suffisent, donc). Si on veut des ordinateurs avec 2,5 Po en mémoire vive, il faut en revanche patienter encore un peu.
Le processeur
Des puces en silicium (source)
Le processeur effectue les calculs de l’ordinateur : il travaille sur les données en mémoire c’est le résultat de ce travail qui induit les changements que l’on voit à l’écran, sur le réseau ou sur le disque dur.
Si chaque composant de l’ordinateur possède ses propres puces électroniques et son propre registre mémoire (la mémoire graphique est ainsi distincte de la mémoire vive centrale), c’est le processeur central (CPU) qui gère la coordination de l’ensemble des composants en modifiant des bits dans la mémoire.
Le cerveau, en plus d’avoir un module mémoire, fait la même chose : les yeux, les oreilles, les mains : tous ceux-ci sont des périphériques dont la coordination est assurée par le cerveau, au moyen de signaux électriques nerveux.
Si un processeur peut effectuer une seule opération à la fois, le cerveau peut en faire plusieurs : il gère ainsi la respiration en même temps que la marche, et il peut s’occuper de la vision en même temps que l’audition. Il est en revanche très difficile d’écouter ou de regarder deux choses à la fois. Je dirais que les périphériques sont monotâches, mais que le cerveau est multitâches et peut faire des choses en arrière-plan.
Concernant la puissance de calcul, les ordinateurs les plus puissants du monde sont les super-calculateurs. Le plus puissant d’entre eux en 2015 est l’ordinateur chinois Tianhe-2 : il est ainsi composé de 260 000 processeurs, possède 1 375 Tio de mémoire vive et une mémoire de masse de 12,4 Po.
La puissance de calcul est mesurée en flops (FLOPS = FLoating-point Operations Per Second) : 1 flops correspond à une opération à virgule flottant par seconde. Tianhe-2 effectue ainsi 33 860 000 de milliards d’opérations par seconde (33,86 Pflops).
C’est beaucoup, mais le cerveau humain en fait beaucoup plus : pour simuler juste 1 seconde de temps de cerveau, il a fallu au superordinateur K et ses 86 000 processeurs 40 minutes de calcul. Dit autrement, ce que 86 000 processeurs font en 40 minutes, le cerveau humain le fait en une seconde.
Si on extrapole, le cerveau humain aurait ainsi une puissance de calcul de 1 zettaflop, soit 1 000 milliards de milliards de mille sabords d’opérations par seconde. D’autres sources disent que le cerveau ne fait « que » 5 Pflops, ce qui est déjà pas mal, mais quand même moins que les derniers super-calculateurs.
Dans les deux cas, il ne faut pas oublier que le cerveau tient dans une tête humaine, alors qu’un super-ordinateur occupe tout un étage dans un immeuble.
La consommation en énergie est également intéressante à évaluer : si un ordinateur portable consomme autour de 80 W et qu’un super-calculateur consomme plusieurs mégawatt, le cerveau consomme 12,6 W (source). Ça semble peu, mais ça correspond à 20% de l’énergie produite par le corps, pour seulement 2% de sa masse. C’est pour ça que l’idée d’un cerveau qui n’utilise que 10% de ses capacités est biologiquement contestable : jamais l’évolution et la nature ne conserveraient les 90% inutiles d’un organe aussi consommateur d’énergie.
Les capteurs
Un microphone : capteur sonore (source)
Les capteurs de notre corps sont les yeux, les oreilles, le nez, les doigts. Tout ce qui correspond à nos sens, en fait. Voyons tout cela.
Les yeux sont nos caméras : ils distinguent la lumière : son intensité, sa couleur, les contrastes… C’est tout ce qu’il fait : tout le traitement est ensuite effectué par le cerveau.
Lorsque Apple a sorti son iPhone® avec l’écran « rétina », un des arguments de vente était que la résolution de l’écran était supérieure à celle de l’œil humain : l’image sur ce téléphone en serait alors parfaite et les pixels invisibles.
Le blog Bad Astronomy a entrepris de vérifier l’affirmation d’Apple et en a conclu que l’écran était réellement « rétina » pour un œil moyen.
La résolution de l’écran rétina était alors de 326 pixels par pouce (ppp). L’œil moyen disposerait lui d’une résolution de 286 ppp et l’œil parfait de 477 ppp.
Cette résolution permet à l’œil parfait de distinguer une règle de 30 cm à une distance de 1770 mètres comme étant un peu plus qu’un simple point.
La définition de l’œil, c’est à dire le nombre de pixels dont l’œil dispose serait quant à elle de 576 Mpx (source), soit bien au dessus de la définition de n’importe quel appareil photo numérique actuel.
Et tout ça, l’œil peut le voir en couleur.
La couleur correspond à l’énergie transportée par un rayon lumineux : l’œil est donc sensible à l’énergie portée par les rayons lumineux. Vu que l’œil détecte toutes les couleurs entre le rouge et le bleu, soit les photons dont l’énergie se trouve entre 1,6 eV et 3,3 eV. En dessous la lumière est de l’infrarouge et au-dessus ce sont les ultra-violets, et l’œil ne sait plus les détecter.
Les capteurs photo CCD actuellement utilisés dans les appareils photo numériques n’ont peut-être pas une résolution ou une définition d’image aussi élevée que nos yeux, mais leur sensibilité est légèrement plus grande. Il est ainsi possible que votre appareil photo numérique voie certains rayons infrarouge : vous pouvez utiliser votre téléphone pour voir la LED de la télécommande de votre TV.
D’autres capteurs optiques peuvent voir tous les infrarouges, les ultra-violets et même les ondes radio, les rayons X et gamma. Là où l’œil ne voit que la lumière visible, la technologie permet en fait de voir tous les types de rayonnements.
Il en va de même pour l’ouïe : les oreilles ne peuvent capter les ondes sonores que si leur fréquence se trouve entre 20 Hz et 20 000 Hz environ. En dehors de ces zones, l’oreille humaine n’entend pas (certains animaux peuvent entendre les ultrasons ou les infrasons). Concernant la résolution des oreilles, les personnes qui ont l’oreille absolue ou bien entraînée peuvent différentier n’importe quelles fréquences, même très proche. Là aussi, la technologie rattrape le vivant et on peut faire des capteurs avec une sensibilité plus grande que l’oreille.
L’odorat est un autre sens qui est assez particulier et souvent ignoré voire sous-estimé. Il correspond en fait à la capacité du corps humain à détecter la forme géométrique des molécules. Les molécules odorantes sont captées par les récepteurs sur des cellules spécialisées : les molécules peuvent s’y fixer en fonction de leur géométrie. L’humain serait ainsi capable de distinguer 1 000 milliards d’odeurs différentes. Une chose similaire pour le goût : ce sont des récepteurs qui distinguent les molécules.
Ceci n’est pas sans quelques petites aberrations : certains récepteurs à molécules font également office de détecteur de chaleur. Ainsi, la molécule de menthol active le récepteur du froid, et le composé « 8-méthyl-N-vanillyl-6-nonénamide » (la capsaïcine) active le récepteur de chaleur. C’est pour cette raison que manger de la menthe donne une sensation de froid et que manger un piment (contenant de capsaïcine) donne une sensation de chaud.
La sensitivité des doigts est également importante : certaines sources déclarent qu’on peut sentir des objets d’une taille de 13 nanomètres. Si le doigt faisait la taille de la Terre, alors on pourrait sentir la différence entre une voiture et une maison.
Tout ceci est remarquable, car le cerveau est relié à chaque terminaison nerveuse du corps et doit traiter toutes les informations… en même temps… pour tous les sens à la fois !
Le coût de production
Le corps humain a la même composition que l’univers : une majorité d’hydrogène, un peu d’oxygène, de carbone et d’azote, et une minorité d’autres éléments. Le calcium, qui est important pour nos os ne constitue que 1,5% du poids de notre corps. On trouve aussi 14 µg d’or :
Élément :
% :
Masse/kg :
Coût au kg/$ :
Valeur/$ :
O
Oxygène
65
49,14
0,20
9,83
C
Carbone
18
18,29
0,01
0,18
H
Hydrogène
10,2
8,00
0,20
1,60
N
Azote
3,1
2,06
0,20
0,41
Ca
Calcium
1,6
1,14
0,10
0,11
P
Phosphore
1,2
0,89
1,00
0,89
K
Potassium
0,25
0,16
650,00
104,00
S
Soufre
0,25
0,16
0,10
0,02
Na
Sodium
0,15
0,11
250,00
28,57
Cl
Chlore
0,15
0,11
1,00
0,11
Mg
Magnésium
0,05
0,02
3,00
0,07
Fe
Fer
6,00E-03
4,80E-03
0,20
0,00
F
Fluor
3,70E-03
2,97E-03
2,000,00
5,94
Zn
Zinc
3,20E-03
2,63E-03
2,00
0,01
Si
Silicium
2,00E-03
1,14E-03
2,00
0,00
Rb
Rubidium
4,60E-04
7,77E-04
10,000,00
7,77
Sr
Strontium
4,60E-04
3,66E-04
1,000,00
0,37
Br
Brome
2,90E-04
2,97E-04
50,00
0,01
Pb
Plomb
1,70E-04
1,37E-04
0,40
0,00
Cu
Cuivre
1,00E-04
8,23E-05
7,00
0,00
Al
Aluminium
8,70E-05
6,86E-05
2,00
0,00
Cd
Cadmium
7,20E-05
5,71E-05
10,00
0,00
Ce
Cerium
5,00E-05
4,57E-05
50,00
0,00
Ba
Barium
3,10E-05
2,51E-05
60,00
0,00
Sn
Étein
2,40E-05
2,29E-05
20,00
0,00
I
Iode
1,60E-05
2,29E-05
2,00
0,00
Ti
Titane
1,30E-05
2,29E-05
8,00
0,00
B
Bore
6,90E-05
2,06E-05
6,000,00
0,12
Se
Sélénium
1,90E-05
1,71E-05
53,00
0,00
Ni
Nickel
1,40E-05
1,71E-05
20,00
0,00
Cr
Chrome
2,40E-06
1,60E-05
20,00
0,00
Mn
Manganèse
1,70E-05
1,37E-05
5,00
0,00
As
Arsenic
2,60E-05
8,00E-06
5,00
0,00
Li
Lithium
3,10E-06
8,00E-06
100,00
0,00
Hg
Mercure
1,90E-05
6,86E-06
40,00
0,00
Cs
Césium
2,10E-06
6,86E-06
3,000,00
0,02
Mo
Molybdène
1,30E-05
5,71E-06
300,00
0,00
Ge
Germanium
1,30E-05
5,71E-06
2,000,00
0,01
Co
Cobalt
2,10E-06
3,43E-06
200,00
0,00
Sb
Antimoine
1,10E-05
2,29E-06
300,00
0,00
Ag
Argent
1,00E-06
2,29E-06
700,00
0,00
Nb
Niobium
1,60E-04
1,71E-06
180,00
0,00
Zr
Zirconium
6,00E-04
1,14E-06
600,00
0,00
La
Lanthane
2,00E-04
9,14E-07
1,500,00
0,00
Te
Tellure
1,20E-05
8,00E-07
240,00
0,00
Ga
Gallium
1,20E-05
8,00E-07
1,800,00
0,00
Y
Yttrium
1,20E-05
6,86E-07
2,000,00
0,00
Bi
Bismuth
1,20E-05
5,71E-07
400,00
0,00
Tl
Thallium
1,40E-05
5,71E-07
500,00
0,00
In
Indium
1,40E-05
4,57E-07
2,000,00
0,00
Au
Or
1,40E-05
2,29E-07
40,000,00
0,01
Sc
Scandium
1,40E-05
2,29E-07
10,000,00
0,00
Ta
Tantale
1,40E-05
2,29E-07
200,00
0,00
V
Vanadium
2,60E-05
1,26E-07
50,00
0,00
th
Thorium
2,00E-07
1,14E-07
-
-
U
Uranium
1,30E-07
1,14E-07
-
-
Sm
Samarium
5,00E-09
5,71E-08
-
-
W
Tungstène
5,00E-09
2,29E-08
-
-
Be
Beryllium
5,00E-09
4,11E-08
-
-
Ra
Radium
1,00E-17
0,00E+00
-
-
Considérant seulement ces éléments, on estime qu’un humain moyen coûterait environ 160 $ en éléments chimiques (source), dont 100 $ rien que pour les 160 grammes de potassium.
Maintenant, le même corps, considérant le coût d’un organe (par exemple un foie ou un cœur à transplanter), et toutes les molécules ou cellules qu’il contient (globules, neurones, etc.) coûteraient environ 45 millions de dollars une fois assemblé.
On peut donc conclure que notre cerveau, manifestement le plus puissant ordinateur du monde, est sûrement aussi le plus cher de tous.
Suite à mon article sur le thermomètre de Galilée, dont le fonctionnement peut être mal interprété, en voici un autre à propos d’un objet décoratif (et éducatif) et beaucoup moins connu : le radiomètre de Crookes, aussi appelé « éolienne solaire ».
Cet appareil, qu’on aurait tendance à trouver dans un labo plutôt que le salon est sympathique aussi : c’est une sorte d’hélice posée sur une aiguille, le tout dans une bulle en verre sous vide. Les pales des hélices ont toutes une face noire et une face brillante. L’hélice se met à tourner quand on l’éclaire :
↑ Un radiomètre de Crookes. Pour le voir en action, voir cette vidéo.
Ce qui est le plus amusant avec cet appareil, c’est que son fonctionnement est contraire à ce pourquoi il a été inventé. Cet appareil, inventé en 1873 par Sir William Crookes était destiné à démontrer la pression de radiation : c’est la pression exercé par la lumière.
À l’époque, l’hypothèse avait en effet été émise que la lumière exerçait une pression : il serait alors possible de pousser un objet simplement en l’éclairant (cette hypothèse a par la suite été validée et de nos jours, la Nasa utilise des sondes avec une voile solaire qui utilise ce principe pour voyager dans le vide).
Pour Crookes, une façon de démontrer l’hypothèse était donc de faire une hélice avec les pales noires d’un côté et brillantes de l’autre, le tout sous vide. La face noir absorbant la lumière, la poussée proviendrait alors de la face brillante : vu que la lumière « rebondit » dessus, elle pousserait alors l’hélice du même coup.
Quand Crookes plaça son radiomètre sous une source de lumière, l’hélice se mit à tourner… dans le sens inverse : la face noir poussant la face brillante, ce fut donc exactement le contraire de ce qui était attendu !
Le problème du radiomètre de Crookes n’était pas un souci de conception, mais un problème de technologie : pour que la très faible pression radiative ($10^{−11}\text{ bar}$) de la lumière puisse être mise en évidence, il faut un vide presque absolu et l’absence de frottements la plus totale possible. Les moyens de l’époque n’était pas suffisants pour faire ça, et il en résultait que le « vide » régnant dans l’enceinte en verre n’était que partiel ($10^{−5}\text{ bar}$).
Albert Einstein calcula que le mouvement des molécules de l’air suffisaient pour interférer et surpasser avec la pression radiative : le côté noir de la plaque chauffant d’avantage, la couche d’air à son contact direct chauffe aussi et la pression augmente d’avantage du côté noir. De plus, Osborne Reynolds montra que l’air qui se trouve sur les bords des pales de l’hélice diffusaient du côté brillant vers le côté sombre malgré la différence de pression déjà en place, augmentant encore peu cette différence.
Le résultat est donc que l’air dans le vide partiel agit comme un moteur thermique dont la source de chaleur est la lumière, indépendamment de la pression de radiation.
Un vide beaucoup plus poussé et une absence de frottements auraient à l’époque pu permettre une rotation uniquement par la pression de la lumière, et donc dans dans le sens attendu. Un vide moins poussé, quant à lui, empêche toute rotation à cause des frottements de l’air.
Un véritable détecteur de la pression de radiation fut mis au point en 1901 par Ernest Fox Nichols : il consistait en une fine fibre de quartz au bout de laquelle étaient suspendus deux miroirs d’argent. La fibre se torsadait avec un angle plus ou moins important selon l’intensité de l’éclairage. Sans rotation, le radiomètre de Nichols pouvait fonctionner même dans un vide partiel de $10^{−1}\text{ bar}$ et avec de bon résultats.
La conclusion ici est double. Premièrement, certains dispositifs ont des comportements étranges, comme le Radiomètre de Crookes, dont les pales se mirent à tourner dans le sens opposé à celui que tout le monde attendait. Et deuxièmement, ce n’est pas parce que le radiomètre de Crookes ne fonctionnait pas que la pression de radiation était une idée fausse : la pression de radiation existe et est présente à chaque fois qu’on éclaire quelque chose. Le radiomètre de Crookes ne constitue simplement pas l’équipement adapté pour le mettre en évidence (il a fallu attendre trois décennies pour que Nichols fabrique un appareil qui puisse mettre cette pression en évidence).
L’étrangeté en sciences, c’est ce qui permet de faire avancer le monde : et la véritable avancée ce n’est pas quand on s’exclame « eureka », mais plutôt quand on se dit « tient, ça c’est étrange… ».
Le plutonium est un élément mystérieux dont tout le monde entend parler mais je suis à peu près sûr que personne n’en a vu en vrai. L’occasion donc de le présenter.
Un petit échantillon de ce métal est à la base de couleur grise argentée mais si on le laisse à l’air libre, la couche d’oxydes qui se forme à sa surface lui donne diverses couleurs par interférences lumineuses (le même principe que sur une bulle de savon).
Ceci dit, cette description uniquement visuelle n’est pas très amusante. Pour rigoler un peu, donc, voyons à quoi ressemblerait un gros bloc de plutonium.
Prenons pour cela un cube de 10 cm de côté : s’il était rempli d’eau il pèserait tout juste 1 kg. Le même cube de 10 cm en plutonium pèserait 19,8 kg : cette masse volumique fait de métal l’un des plus denses du tableau périodique (plus que l’or ou le tungstène).
Le plutonium est aussi un élément à la fois fissile et radioactif : la désintégration radioactive du plutonium par la fission entretient cette même fission par une émission de neutrons. Si la masse de plutonium est suffisante (on parle de masse critique), alors la fission se fait selon une réaction en chaîne (effet boule de neige) avec une libération d’énergie considérable. Pour le plutonium 239, la masse critique est de 10 kg : votre cube de plutonium à lui tout seul, constitue donc une bombe atomique !
Dans la confection de bombes atomiques, cette masse critique a pu être abaissée à seulement 5,3 kg, en utilisant des réflecteurs à neutrons. Les neutrons sont en effet émis au sein même du plutonium, et il faut que ce neutron puisse engendrer une seconde désintégration, puis une troisième, etc. Si l’échantillon de matière est trop petite (inférieure à la masse critique), les neutrons peuvent sortir de l’échantillon sans produire de réactions en chaine. Utiliser 5,3 kg de plutonium est donc à priori trop faible… à moins de forcer les neutrons à rester dans le plutonium : c’est le rôle des réflecteurs à neutrons.
«Titiller la queue du dragon » (image)
Lors des recherches qui ont permis de mettre au point la bombe atomique, la manipulation de réflecteurs en demi-sphères au béryllium, dans lesquelles étaient posée une boule de plutonium se faisait parfois avec un simple tournevis. Or, si les deux réflecteurs se mettaient en place, le cœur de plutonium devenait critique et pouvait exploser avec la puissance d’une bombe atomique. L’expérience avec le tournevis a été nommée « titiller la queue du dragon », tellement elle était risquée et tant les conséquences pouvaient être catastrophiques. Des accidents arrivèrent d’ailleurs : en 1946, le tournevis glissa de côté, et le cœur devient critique durant un court instant, ce qui émit une importante quantité de radiations aux opérateurs (celui qui manipulait le tournevis mourut seulement 9 jours plus tard de l’exposition aux rayonnements)…
Revenons en à notre cube de plutonium : imaginons qu’il n’explose pas comme une bombe A.
Dans ce cas, la simple radioactivité du plutonium suffit à le chauffer : il est dit qu’un petit bloc de plutonium 239 chauffe autant que si on tenait un lapin dans les mains.
Si vous aviez pris du plutonium 238, un isotope, alors le cube fondrait sous sa propre chaleur : le 238Pu est en effet beaucoup plus radioactif que le 239Pu (633 milliard de désintégration par seconde et par gramme) et il émet assez de chaleur pour le chauffer au rouge et le faire fondre.
Un bloc de 1 kg de plutonium 238 émet ainsi environ 500 W de chaleur, et cela en continu durant plusieurs dizaines d’années :
Bloc d’oxyde de plutonium luisant sous sa propre chaleur ↑
Cette forme d’énergie nucléaire est couramment utilisée dans les sondes spatiales telles que New Horizons (qui a survolé Pluton il n’y pas si longtemps) ou Cassini (qui survole Saturne et ses lunes depuis 2006) : New Horizons contient ainsi plus de 10 kg d’oxyde de plutonium 238 au sein d’un générateur thermoélectrique à radio-isotopes: un bloc d’oxyde de plutonium recouvert de thermocouples, qui transforment cette chaleur en électricité, là où des panneaux solaires plus classiques ne suffisent plus à cause de l’éloignement au Soleil.
Cette source d’énergie était aussi utilisée dans certains pacemakers, pour sa longue durée de vie (plus de 20 ans). Elle est aujourd’hui remplacée par les piles au lithium mais certains appareils au plutonium sont encore en usage.
Concernant la santé : en plus d’être super-dense, radioactif, fissile et naturellement chaud, le plutonium est également toxique : c’est un métal lourd et il présente des risques sur la santé similaires à ceux du plomb, du cadmium ou du mercure, de façon indépendante de sa radioactivité, qui vient s’ajouter à tout cela.
Enfin, notons que même si ce métal est nommé d’après Pluton qui était à l’époque considérée comme une planète (comme l’uranium est nommé d’après Uranus et le neptunium d’après Neptune), le plutonium ne sera pas rebaptisé suite à la destitution de Pluton au rang de planète-naine.
Demon Core : le cœur de plutonium surnommée « cœur du démon » après les accidents de 1945 et 1946.
Le film « Les Maîtres de l’Ombre », sorti en 1989 retrace la mise au point de la bombe atomique à Los Alamos. On y voit la scène où le demon-core devient critique.
Quelque soit la discipline, science ou art, le noir et le blanc ont des positions un peu particulières dans la palette des couleurs.
Selon les scientifiques
Les scientifiques diront ainsi que le blanc représente la somme de toutes les longueurs d’onde de la lumière :
Décompostion de la lumière blanche par un prisme (source)
La lumière blanche peut donc être décomposée en lumière colorée, mais également reconstituée : en plaçant deux prismes à la suite, la couleur blanche peut être reconstituée à partir de tous les rayons colorés. C’est Newton qui le premier effectua cette expérience.
Le blanc n’est donc pas vraiment une couleur si on considère qu’une couleur correspond à une longueur d’onde unique, puisqu’il est la somme de plusieurs longueurs d’ondes différentes.
Sauf que… parmi les « couleurs » qui sont une somme de longueurs d’ondes, le blanc n’est pas seul : le magenta, par exemple : il est le résultat du mélange des deux longueurs d’ondes à l’extrémité du spectre : le rouge et le bleu. Il n’y a pas de longueur d’onde « magenta ». Le magenta n’est donc pas une couleur ?
Le noir, quant à lui, ne serait pas non plus une couleur : il représente en fait l’absence de lumière reçue par l’œil. Dans un espace totalement sombre (pas de lumière), notre œil ne capte rien et le cerveau interprète cela comme du noir. De même, un objet est vu noir lorsqu’il ne réfléchit ou n’émet pas de lumière.
Mais de même que pour le blanc, un objet noir n’est pas le seul à présenter ses particularités : l’air par exemple : il ne reflète ni absorbe de lumière. Est-il blanc ? Non, il est transparent.
Scientifiquement, le statut du blanc ou du noir n’est donc pas réellement expliqué avec les arguments habituels.
Selon les artistes
Artistiquement parlant, le blanc et le noir sont utilisés au même titre que toutes les autres couleurs : on les retrouve dans toutes les toiles, photos ou dessins.
Mais là aussi on a à faire à un paradoxe : n’oppose-t-on pas le « noir & blanc » aux autres couleurs ? Ces deux là sont donc souvent mis à part également…
En colorimétrie
En fait, dans la lumière, il n’y a pas que la longueur d’onde (scientifiquement parlant) ou la teinte (artistiquement parlant). Il y a aussi l’intensité : une lumière verte peut ainsi être très diffuse ou au contraire éblouissante.
Si on isole la source de lumière verte, alors le fond de référence serait le noir.
On dit que le noir et le blanc sont des aspects de la luminosité : de la quantité de lumière reçu, indépendamment de la couleur.
En effet, si on peut avoir un objet de couleur magenta (donc à la fois rouge et bleu), il n’est pas possible d’avoir un objet à la fois lumineux (blanc) et non lumineux (noir).
Le noir et le blanc sont en réalité les extrémités de l’échelle de la luminosité, composée de toute une échelle de gris :
En colorimétrie, le blanc et le noir sont indépendants de la couleur, qui sont alors des teintes : rouge, vert, jaune…
Pour faire un effet désiré sur un pixel (et donc sur une image), il faut alors prendre une teinte et la superposer à une luminosité.
C’est ainsi que l’on peut créer des couleurs plus ou moins sombres ou claires à partir d’une même teinte. Pour un objet de couleur rouge, si la luminosité est choisie au maximum, alors on obtient du rouge, si elle est mise au minimum, on obtient du noir (équivalent à aucun éclairage).
N’importe quel objet possède une teinte — à cause de ses pigments — et une luminosité — au cause de la quantité de lumière sous laquelle on l’éclaire.
L’effet observé par le cerveau est donc différent, même si dans l’absolu la couleur des pigments dans le trait de varie en rien.
Conclusion
Le blanc et le noir ne sont des couleurs que selon la définition de la couleur que l’on considère.
En terme de longueur d’onde donc, le blanc et le noir ne sont pas des couleurs (mais alors le magenta, le marron, le rose, le gris… non plus).
Mais en terme de ressenti et de perception, ils le sont : un objet blanc est différent d’un objet rouge par exemple. Dans ce cas, il est préférable d’employer le terme de coloris, qui définit l’effet visuel obtenu, réservant alors le terme de « couleur » à la teinte d’un objet et plaçant le blanc et le noir sur l’échelle à part des luminosités.
J’en ai déjà parlé, Benjamin Franklin (surtout connu pour son engagement politique durant la guerre d’indépendance des États-Unis), était également un grand scientifique.
De ses multiples inventions, la plus sympathique selon moi sont les cloches détectrices d’orage.
Franklin était en effet le premier à avoir compris l’origine électrique des orages et, en plus du paratonnerre qu’il inventa pour protéger les gens durant un orage, il inventa aussi un dispositif qui permettaient de détecter l’approche des orages :
Schéma des double cloches de Franklin (source)
Durant un orage, les mouvements ascendants d’air humide et chaud — moins denses — entraîne des charges électriques en altitude : les gros nuages d’orage se chargent donc progressivement en électricité et le sol se décharge : il se crée alors une différence de potentiel électrique entre le sol et les nuages qui augmente suffisamment pour surpasser la résistance de l’air et provoquer un éclair.
Les cloches de Franklin utilisent le fait que le ciel et la terre ont des charges électriques opposées.
Le principe est le suivant : on dispose de deux cloches fixes, isolées, et espacées de quelques centimètres : l’une est reliée à la terre par un conducteur, l’autre est reliée à l’air par un râteau ou une grille qui prend le vent. Il est important que les deux cloches soient isolées électriquement (par exemple avec une armature en plastique ou en bois). Les deux cloches prennent alors respectivement le potentiel électrique de la terre et de l’air.
De plus, un petit pendule métallique suspendu par un fil isolant se trouve entre les cloches
Quand une brise de vent pousse la bille sur une des cloches, ces deux dernières égalisent leur potentiel électrique, ce qui a pour effet de produire une force répulsive entre les deux. Le pendule est donc renvoyé vers l’autre cloche dont il prend alors son potentiel électrique (opposé à celui de la première), avant d’être repoussé à nouveau vers la première cloche, et ainsi de suite.
Le pendule effectue alors un mouvement de va et viens entre les deux cloches. Un petit son est émis à chaque contact du pendule et de la cloche. Ce mouvement est entretenu tant que l’orage sera là.
Il est possible de faire des cloches de Franklin à la maison, avec très peu de matériaux : tout ce qu’il vous faut, ce sont deux canettes de soda en aluminium, du papier d’alu, une paille (ou tout autre tige en plastique), du fil isolant (fil de pêche par exemple) et du fil conducteur (et une grille métallique : passoire, râteau, fourchette par exemple). Cette vidéo explique le début, mais pour détecter les vrais orages, il faudra juste relier une des canettes à la terre (par exemple en plantant un bout du fil dans le sol) et l’autre canette à l’air (par exemple en la reliant à une passoire ou un râteau qui soit isolé du sol : la passoire filtre l’air et captera son électricité). Si tout se passe bien et si un orage approche, la cloche se mettra a sonner.
Quel que soit l’appareil avec lequel vous lisez ces lignes, il fonctionne grâce aux matériaux semi-conducteurs.
Dans cet article et dans ceux qui vont suivre, on va voir pourquoi les semi-conducteurs sont à la base de toute l’informatique moderne et comment fonctionnent nos appareils informatiques.
Dans cet article : c’est quoi, un semi-conducteur ?
Un semi-conducteur
Un semi-conducteur, comme le silicium, c’est un matériau qui n’est ni tout à fait un conducteur d’électricité, ni tout à fait un isolant. Il peut être soit l’un, soit l’autre selon diverses conditions.
Le caractère conducteur ou isolant prend sa source dans la structure même des atomes : chaque élément du tableau périodique possède un certain nombre d’électrons qui sont agencés autour d’un noyau. C’est cet agencement sous la forme de couches d’électrons, différent selon les éléments, qui est responsable de la conductivité électrique.
Les électrons d’un atomes peuvent avoir plusieurs rôles au sein d’une structure d’atomes :
électrons de cœur : ceux-ci sont proche du noyau et n’interagissent pas vraiment avec les autres atomes ;
électrons de valence : ceux-ci sont sur les couches externes de l’atome et permettent de créer des liaisons interatomiques et de former les molécules ;
électrons de conduction : ceux-ci sont responsables de la circulation du courant électrique.
On peut schématiser l’ensemble sous la forme de couches. Sur le schéma suivant, on a représenté les couches d’électrons de valence et d’électrons de conduction :
(source)
On voit que dans un métal, certains électrons sont à la fois dans la bande de valence et dans la bande de conduction. Cela signifie qu’un métal peut conduire le courant sans autre forme de traitement physico-chimique.
Dans un isolant, par contre, les deux bandes sont séparées par un espace appelé « bande interdite » : cela signifie que les électrons ne peuvent pas s’y trouver. Dans le cas des isolants, les électrons externes sont tous dans la bande de valence et aucun ne se trouve dans la bande de conduction : ces matériaux ne peuvent donc pas conduire l’électricité.
Enfin, dans le cas des semi-conducteurs, au milieu, il existe une bande interdite aussi, mais cette dernière est très fine. Il suffit d’un petit quelque chose pour que les électrons de valence puissent passer dans la bande de conduction et ainsi rendre le semi-conducteur… conducteur. On parvient à faire ça en donnant de l’énergie aux électrons, en les excitant.
Un semi-conducteur est donc un isolant mais qui peut devenir un conducteur très facilement en excitant les électrons de valence : on fait ça en chauffant le matériau, ou en l’éclairant, ou en le soumettant à une tension électrique bien définie.
Par exemple, si on éclaire une plaque photovoltaïque, la plaque devient conductrice et on crée un courant électrique : c’est l’effet photoélectrique.
On dispose donc ici d’une fonction bien intéressante : c’est un isolant qui devient conducteur quand on l’éclaire.
Dans un processeur d’ordinateur, c’est une tension électrique minimale qui permet de rendre le semi-conducteur isolant en dessous et conducteur au dessus.
Croyez-le ou non, c’est ce principe très simple qui est à la base de toute l’informatique.
Le dopage
On a vu qu’il existe une bande interdite dans la structure des semi-conducteurs et des isolants. Un semi-conducteur possède une petite bande interdite que les électrons peuvent franchir si on leur donne l’énergie nécessaire. Plus cette bande est faible, plus l’énergie nécessaire est petite. Ceci est intéressant pour la consommation électrique de nos appareils, mais aussi d’un point de vu plus technique.
Dans un cristal de silicium (le plus commun des semi-conducteurs à ce jour), il faut une énergie de $1,12\text{ eV}$ (soit $1,79×10^{−19}\text{ J}$) pour placer un électron de valence dans la bande de conduction.
C’est une énergie très faible, mais ça reste quand même beaucoup trop pour l’usage qu’on a actuellement des semi-conducteurs.
Le dopage, c’est une technique qui vise à modifier l’énergie nécessaire pour rendre le conducteur un semi-conducteur. Il consiste à injecter dans les cristaux de silicium des atomes bien choisis pour le rendre soit un peu plus conducteurs, soit un peu moins.
Le silicium possède 4 électrons de valence (comme le carbone) : dans un cristal, il se lie donc de façon tétraédrique à 4 autres atomes de silicium :
Structure cristalline du silicium (source)
Il est possible de remplacer certains atomes de silicium par d’autres atomes, qui vont alors modifier la structure des bandes de conduction.
L’atome de silicium possédant 4 électrons de valence, on peut injecter un atome avec 5 électrons de valence : l’atome sera alors dans le cristal avec 4 liaisons mais possédera un électron supplémentaire. Pour ça, on utilise souvent du phosphore (symbole $P$).
Vu que ce type de modification apporte un électron en plus dans le cristal, la bande de conduction est alors globalement négative : on parle de dopage négatif, ou dopage N (le cristal dans son ensemble reste neutre, car le phosphore contient un proton en plus aussi ; c’est juste la bande de conduction qui est négative).
Une autre solution est d’utiliser un dopage au bore (symbole $B$), qui n’a que 3 électrons de valence : le bore sera là aussi bien pris dans un cristal avec 4 liaisons, mais une des liaisons manquera un électron : il sera donc comme « positif » (car il manque comme une charge négative), d’où le nom de dopage P :
Dopages N (avec l’électron en trop) et P (avec le déficit d’électron) — (sources 1 & 2)
Grâce au dopage N, le silicium devient un peu plus conducteur : en effet, l’introduction du phosphore a pour effet de déplacer la bande de conduction vers le bas : les électrons du silicium sont donc plus rapidement conducteurs.
Grâce au dopage P, le silicium devient également un peu plus conducteur : le bore apporte certes « un trou d’électrons », mais ce dernier peut recevoir un électron voisin qui laisse alors un trou derrière lui. Le trou s’est alors déplacé et ceci constitue bien un sorte de déplacement de charges (« virtuellement » positive) et augmente donc la conductivité du matériau également.
Ces deux façons de doper un semi-conducteur sont donc antagonistes : l’une apporte un électron en plus au cristal semi-conducteur et l’autre en retire un.
En combinant deux matériaux dopés de façon différente, on peut faire des composants électriques comme des diodes ou des transistors. Mais ça sera l’objet d’un prochain article !
Pour l’instant, retenez que le silicium est un semi-conducteur car il ne laisse passer le courant que si on excite ses électrons de valence. Il faut pour cela une tension électrique dépassant un seuil minimal propre au matériau.
On utilise le dopage N (négatif) ou P (positif) pour modifier légèrement le seuil de tension mais aussi pour modifier d’autres propriétés du semi-conducteur (qu’on verra dans les autres articles).
Enfin, juste pour la culture, sachez que le silicium n’est pas le seul semi-conducteur existant. Avant lui, les propriétés semi-conductrices du germanium (symbole $Ge$) étaient déjà utilisées dans les tout premiers transistors. Depuis, d’autres composés ont aussi été découvert. Les plus connus d’entre eux sont l’arséniure de gallium ($GaAs$) et le nitrure d'indium ($InN$), bien qu’il en existe beaucoup d’autres.
Le silicium est aujourd’hui massivement utilisé principalement parce qu’il est très abondant sur terre : il représente 25% de la croûte terrestre, et est simple à extraire et à utiliser.
Dans le premier article de cette petite série d’articles, on a vu pourquoi certains éléments sont des semi-conducteurs, comment ils fonctionnent et comment on peut les doper avec d’autres éléments pour leur donner des propriétés plus intéressantes ou utiles.
Pour ce second article, on va voir comment ces semi-conducteurs peuvent former la brique élémentaire de l’informatique moderne : le transistor.
La Diode et le Transistor
La diode est l’équivalent beaucoup plus petite, beaucoup plus pratique, beaucoup plus robuste que les anciennes ampoules à vide utilisées dans les premiers ancêtres d’ordinateurs. Ces ampoules utilisaient une borne émettrice d’électrons à très haute tension et une autre borne qui les réceptionnait. L’ensemble était asymétrique et les électrons ne pouvaient passer que dans un seul et unique sens (le principe de la diode).
Des diodes tripolaires (triiode) au format d’anciens tubes à vide (source)
Ces ampoules à vide étaient grandes, chauffaient, nécessitaient des hautes tensions… bref, l’informatique méritait mieux que ça. Heureusement, depuis on a inventé les circuits intégrés : ce sont des semi-conducteurs gravés qui font office de composants électroniques. Ces derniers sont désormais beaucoup plus petits, ne chauffent pas ou peu et sont bien moins fragiles et moins chers.
Par exemple, le transistor est tellement miniaturisé que votre ordinateur ou votre téléphone en contient plusieurs centaines de millions, voire plusieurs milliards, sur une simple puce de silicium.
Quelques exemples de transistors simples en tant que composants pour l’électronique (source)
La diode, comme son nom laisse penser (le « di- »), est composé de deux morceaux de semi-conducteurs : un morceau de semi-conducteur dopé P, et un morceau dopé N (on parle de diode PN).
Le transistor, lui, est un composant à trois bornes qui est composé de deux diodes PN collées dos à dos de façon à former soit une suite NPN) soit une suite PNP si on les accole dans l’autre sens. NPN et PNP sont deux types de transistors.
Anatomie d’un transistor
Comme je l’ai dit au dessus, le transistor est un tripôle correspondant à une juxtaposition de semi-conducteurs dopés N et P. Dans ce qui suit, on prendra comme base le transistor NPN en silicium.
Dans les faits, c’est un sandwich de silicium P entre deux tranches de silicium N :
Schéma et symbole du transistor
Le fait que l’on utilise des semi-conducteurs dopés différemment, on observe plusieurs phénomènes dans le transistor, notamment aux jonctions NP et PN.
Souvenez-vous, les semi-conducteurs dopés N sont surchargés d’électrons : le cristal de semi-conducteur contient des électrons « libres » entre les atomes. Les semi-conducteurs dopés P contiennent des trous d’électrons : des emplacements où se trouve une liaison cristalline mais où il manque un électron.
Aux jonctions, et uniquement aux jonctions, certains électrons de la partie N va aller boucher les trous de la partie P.
On se retrouve donc avec les jonctions qui se retrouvent à la fois sans électrons libres et sans trous : les électrons du N sont partis boucher les trous du P. Cette jonction ne contient donc plus de charges conductrices introduites grâce au dopage :
Ce déplacement d’électrons au sein du cristal de silicium dopé va générer des régions chargées au niveau des jonctions : les zones N vont devenir positives (le phosphore se trouve ionisé positivement, car son électron en trop est parti) et les zones P de l’autre côté vont se retrouver négatives (le bore va se retrouver ionisé négativement, car son trou est bouché par un électron).
Si les électrons et les trous ne participent plus à la conduction du courant au niveau de ces jonctions, ils représentent donc une différence de charge au niveau moléculaire :
À ce stade, le transistor n’est pas encore branché dans un circuit : les zones chargées sur les jonctions sont présentes de façon naturelle au sein de la matière qui compose le transistor, simplement parce que des électrons se sont déplacés. Ce phénomène de productions de zones chargées au niveau des jonctions est cruciale pour le fonctionnement du transistor. En fait, c’est là que naissent toutes les propriétés électroniques des transistors.
Fonctionnement d’un transistor
Voyons ce qui se passe quand on branche le transistor dans un circuit.
Le transistor dispose de trois bornes :
le collecteur ;
la base ;
l’émetteur.
Le collecteur et l’émetteur sont techniquement symétriques. La base est est un peu particulière.
Commençons par brancher le collecteur et l’émetteur dans un circuit et à mettre le courant (on considère que la base n’est reliée à rien du tout).
Les premiers électrons qui vont arriver au collecteur vont être naturellement attirés par la région positivement chargée près de la jonction NP.
Une fois que cette région sera occupée par les électrons, ces derniers vont se retrouver devant à un mur : ils seront repoussés par la région négative dans la partie P du transistor. Les électrons ne peuvent donc pas passer vers l’émetteur.
De l’autre côté, les électrons de l’émetteur finissent par être aspirés dans le circuit, mais ils sont également attirés par la région positivement chargée à la jonction PN. De ce fait, le courant ne passe pas là non plus.
À ce stade, le transistor bloque complètement la circulation du courant.
(Évidemment, si on augmente la tension aux bornes C et E du transistor, le courant finira par passer quand-même : la différence de potentiel du circuit sera plus forte que les effets de répulsion qui empêchent les électrons de passer, mais dans ce cas là, ça correspondra au claquage du composant et résulterait également en sa destruction, ce qui n’est donc pas un comportement normal ni souhaité.)
Maintenant, mettons la base du transistor sous tension et observons ce qui se passe :
À cause de cette tension positive sur la base, des électrons commencent par être retirés de la base.
La conséquence de cela, c’est que les électrons du collecteur ne subissent plus de répulsion et ils peuvent maintenant se mettre à circuler sous l’effet de la tension principale entre le collecteur et l’émetteur.
En arrivant sur l’émetteur, les électrons vont boucher les trous (qui sont positifs), puis vont pouvoir passer dans le circuit.
La simple présence du courant sur la base suffit à supprimer la barrière d’électrons qui empêchait le courant principal entre le collecteur et l’émetteur de passer. Si on supprime ce courant de la base, les électrons qui vont arriver par le collecteur vont s’arrêter au niveau des trous dans la région P et finir de nouveau par bloquer le courant entre le collecteur et l’émetteur !
On a donc un comportement très particulier :
en appliquant une petite tension à la base, le courant principal entre le collecteur et l’émetteur peu passer ;
en supprimant cette tension à la base, le courant entre le collecteur et l’émetteur est coupé.
Ce comportement peut sembler anodin, mais il ne l’est pas : cet effet, parfois nommé effet transistor permet de contrôler un courant principal (circuit CE) avec un petit courant secondaire (sur la borne B). Il s’agit donc d’un sorte d’interrupteur électronique.
Le transistor est un interrupteur contrôlé électroniquement, sans partie mécanique.
Vous devinez peut-être la suite : si on branche plusieurs transistors à la suite, avec la sortie d’un transistor branché à la base d’un autre, on obtient un circuit où un transistor peut contrôler ceux qui le suivent. Avec un grand nombre d’enchaînements de ce type, on arrive à faire des circuits plus évolués, comme les portes logiques.
Les portes logiques
Si on met deux transistors en série, alors le second, quelque soit son état (bloquant ou passant), aura un comportement qui dépendra du premier.
Une chose est sûre cependant, c’est que pour que le second laisse passer le courant, il faut obligatoirement que le premier laisse passer le courant lui-aussi :
si les entrée A et B sont nulles (tension nulle), alors la sortie est nulle ;
si A est nulle mais que B n’est pas nulle, alors la sortie est nulle ;
si B est nulle mais que A n’est pas nulle, alors la sortie est nulle ;
si A et B ne sont pas nulle, alors la sortie n’est pas nulle (la tension à la sortie est (ici) de 5 V).
On appelle ce dispositif une « porte ET », dans le sens où le courant passe uniquement si l’entrée A et l’entrée B sont sous tension.
Il existe aussi la porte OU, où le courant passe à la condition que l’une des entrées au moins est sous tension.
Les portes logiques dans ce genre existe sous plein de formes. On a vu ET, j’ai mentionné OU. Citons aussi la porte NON (dont la sortie est l’inverse de l’entrée), la porte NON-ET (qui inverse la sortie d’une porte ET), la porte NON-OU, la porte OU-Exclusif (qui est une porte où l’une des entrées seule doit être sous tension, mais surtout pas les deux).
Ces portes logiques permettent de comparer des entrées (A et B) : si les deux entrées sont à 0 V, alors la porte ET ou OU afficheront également 0 V en sortie. Mais la porte Non-OU ou Non-ET afficheront 5 V en sortie.
Ces portes constituent le début des fonctions opératoires de base en électronique.
Avec quelques-unes de ces portes logiques, on commence à faire des calculs encore plus évoluées. Par exemple, on peut faire un additionneur sur deux bits avec retenue à l’aide de seulement cinq portes logiques :
L’addition se fait ici en binaire. Si je branche les bornes A et B, j’obtiens en sortie l’addition de A et B :
La borne Re, c’est pour brancher la sortie Rs (la retenue) d’un montage précédent identique. En grand nombre, ces montages entiers mis bout à bout permettent de faire des additions binaires beaucoup plus grandes !
Différents agencements permettent de faire des convertisseurs, des multiplicateurs, des diviseurs… Toutes les fonctions mathématiques de base, en fait, et avec elles, toutes les applications imaginables dans les programmes d’ordinateur.
Croyez-le bien : en grand nombre et assemblés, ce genre de montages, composés uniquement de transistors en silicium dopé, sont à la base des processeurs et des composants actifs dans tous les ordinateurs, smartphones et systèmes numériques !
Dans le prochain article, je parlerai d’une fonction un peu particulière obtenue avec les transistors : la fonction mémoire. Des clés USB aux cartes mémoires en passant par les disques durs SSD, tous ces systèmes de stockage de données utilisent en effet des transistors pour stocker les données numériques sur le long terme.
ÉDIT : suite à une remarque, je l’ajoute quand-même : ici je n’ai présenté que le comportement en interrupteur contrôlé électroniquement. Il y d’autres applications à ça, comme le transistor amplificateur (qui n’est cependant qu’un effet secondaire au mode interrupteur).
Les précédents articles parlaient de la nature d’un semi-conducteur et son fonctionnement et comment on les utilisait pour créer des transistors.
Désormais on va voir comment utiliser les transistors pour faire un composant essentiel à nos ordinateurs et nos appareils numériques : la mémoire.
Les disquettes et les disques durs à plateau stockent l’information de façon magnétique : les octets sont écrits sous la forme de minuscules aimants sur le disque. En lisant les intensités du champ magnétique sur le disque, on retrouve alors nos octets initiaux.
Pour la mémoire flash, présente les clé USB, les cartes mémoire ou les lecteurs SSD, l’information est stockée à l’aide de transistors.
Ce qui est intéressant ici c’est que l’information stockée persiste électriquement au sein du composant même en l’absence d’alimentation électrique. Ceci est le contraire de la mémoire utilisée dans les barrettes de mémoire vive (RAM) qui perdent leur contenu quand l’ordinateur est hors-tension.
MOSFET à grille flottante (ou FGMOS)
À vos souhait.
Le MOSFET (pour Metal Oxide Semiconductor Field Effect Transistor, ou transistor à effet de champ à oxyde métallique) est un type particulier de transistor. Le fonctionnement de ces transistors est un peu différent mais l’effet obtenu est le même que celui que l’on a vu dans l’article précédent.
On a vu que la base du transistor est une borne qui permet de contrôler le transistor en lui appliquant une tension électrique. Pour le transistor à effet de champ, ce n’est plus un courant électrique qui vient « aspirer » les électrons qui bloquaient le courant principal, mais un champ électrique distant qui vient les attirer. La borne elle-même est isolée du circuit principal :
Si la base n’est soumise à aucune tension, le transistor à effet de champ est bloquant.
Par contre, quand on applique une tension électrique sur la base, il va se créer un champ électrique assez puissant pour repousser les charges positives (les trous) et attirer toutes les charges négatives (les électrons). Il se forme donc une zone entièrement conductrice entre le collecteur et l’émetteur où le courant va pouvoir passer :
Ici on a simplement reproduit l’effet transistor mais avec un système différent. Il n’y a pas encore d’effet mémoire.
Pour obtenir un système de mémoire, il faut aller plus loin : il faut ajouter un conducteur entre deux couches d’isolants, comme ceci :
La partie en noir est un simple morceau de conducteur. On l’appelle « grille flottante » (floating gate) parce qu’elle est isolée du reste. C’est cette grille flottante qui va permettre l’effet mémoire.
La grille flottante : origine de l’effet mémoire
Si on ne considère que la grille flottante, elle peut être dans deux états :
chargée électriquement, en électrons (comme un condensateur) ;
non-chargée électriquement (neutre en charges).
Si cette grille est chargée en électrons, ces derniers vont repousser tous les électrons du semi-conducteur P. Si on applique une tension sur la base, la champ électrique produit ne suffira pas à attirer les électrons dans le bloc P, car la grille lui en empêche.
Au contraire, si la grille est neutre (déchargée) et qu’une tension est appliquée sur la base, le champ électrique pourra attirer les électrons de la partie P sans que ceux-ci soient repoussés : le transistor devient alors passant :
L’intérêt de tout ça, c’est que puisque la grille est isolée électriquement, son état va persister sur le long terme : c’est là que se joue l’effet mémoire.
Lecture et écriture
Lecture dans la mémoire
La phase de lecture est assez rapide et plutôt simple : il suffit de voir si le transistor est bloquant ou passant.
En effet, le simple fait de connaître l’état du transistor permet de déduire l’état de la charge sur la grille flottante.
Le transistor est passant (bit = 1) : la grille est déchargée ;
Le transistor est bloquant (bit = 0) : la grille est chargée en électrons.
Et c’est tout ce qu’il y a à faire pour lire le contenu d’un seul bit d’une mémoire de type FG-MOSFET.
Écriture dans la mémoire
Pour l’écriture, c’est une toute autre histoire. En effet, la fonction mémoire est assurée par un composant électrique isolé du reste du circuit. À priori, modifier cette charge n’est pas possible. Mais il y a une astuce, et pour ça il faut faire appel à la physique quantique et l’effet tunnel.
En physique quantique, comme l’a montré Schrödinger, les électrons comme toutes les particules peuvent être vues comme une onde. Onde et particule sont en fait différentes approches pour visualiser une seule et même entité (un électron).
Un électron est alors modélisé par une fonction d’onde dont l’amplitude, fixe, correspond à son énergie. L’électron peut se déplacer tant qu’il ne rencontre pas un champ d’énergie plus élevé, qui constitue alors ce qu’on appelle « une barrière de potentiel [énergétique] » :
(source)
Il se trouve que la couche d’isolant entre la grille flottante et la borne B constitue une barrière de potentiel de ce type : c’est la raison pour laquelle l’électron ne peut pas quitter la grille flottante en passant par la couche d’isolant.
Néanmoins, d’après l’équation de Schrödinger, la fonction d’onde ne s’arrête pas de façon nette devant la barrière de potentiel : en réalité, l’onde pénètre dans la barrière. Dans les fait, l’onde pénètre faiblement et son énergie décroît de façon exponentielle à l’intérieur de la barrière.
Ainsi, si la barrière de potentiel n’est pas épaisse, l’énergie de la fonction d’onde est non-nulle quand elle arrive de l’autre côté de la barrière de potentiel : l’électron arrive à s’échapper de l’autre côté :
Concrètement, dans la cas d’une barrière étroite, une partie de l’onde finit par s’échapper de l’autre côté de la barrière. De façon simplifiée, dans le cas de la grille flottante, c’est comme si des électrons traversent la couche d’isolant et finissent par décharger la grille flottante. Ce n’est pas ce qu’on veut.
Si on utilise une barrière plus large, alors l’onde s’affaiblit tellement face à la barrière de potentiel, que dans les faits, rien ne passe de l’autre côté : la grille peut alors rester chargée des années durant.
Ok, donc on sait qu’il faut utiliser une barrière large pour empêcher la mémoire de s’effacer avec le temps. On comprend qu’il faut donc utiliser une épaisseur suffisante d’isolant entre la borne de la base et de la grille. Mais comment on fait pour modifier la charge de la grille ?
Et bien on va réduire la barrière de potentiel lors de l’écriture et l’élargir pour le stockage à long terme, sans toucher à l’épaisseur physique de la couche d’isolant.
Pour parvenir à ça, on va appliquer une tension importante sur la base.
En simplifiant, ceci va élever le niveau d’énergie des électrons et déformer la barrière de potentiel pour qu’elle soit moins épaisse. Selon le signe de la tension (positive ou négative), les électrons passeront de la base vers la grille flottante (chargement de la grille) ou dans le sens inverse (déchargement), simplement par effet tunnel.
C’est donc un comportement issu purement de la physique quantique qui permet d’écrire dans la mémoire d’une clé USB.
Une autre solution (utilisé dans d’autres types de mémoire) est d’utiliser l’injection d’électrons chauds de la partie centrale P du transistor vers la grille flottante en leur donnant une vitesse (=énergie) suffisante pour leur permettre de traverser la couche isolante. Le qualificatif de « chaud » réfère l’énergie élevée des électrons.
Limites de ce type de mémoire
Si la lecture d’un bit de la mémoire est sans réelle contrainte technique, la phase d’écriture impliquent l’emploi de hautes tensions ou de conditions plutôt extrêmes pour le transistor. C’est là une des raisons qui fait que le nombre de cycles d’écriture des lecteurs SSD est limité.
Une autre limitation, c’est comme on a vu, le fait que la couche d’isolant doit être suffisamment épaisse pour éviter que les électrons ne s’échappent tout seuls de la grille. L’épaisseur de l’isolant constitue une des limites à la miniaturisation des composants.
Le même problème est d’ailleurs présent dans pratiquement tous les transistors, qu’ils soient dans un module mémoire ou pas : si l’architecture des transistors est trop petite, les électrons finissent par passer d’une borne à l’autre sans rien faire, simplement à cause de l’effet tunnel.
Mémoire NAND ou NOR ?
On a vu ce-dessus comment fonctionnent ou comment lire ou écrire un seul bit dans un seul transistor. Dans la réalité, la mémoire informatique vient sous la forme de modules avec plusieurs milliards de transistors. C’est la façon d’organiser ces transistors entre-eux qui varie selon le type de mémoire.
Si l’on utilise des transistors en série, on obtient de la mémoire NAND (nom donné à cause des portes NAND, où les deux transistors sont en série). Si on place les transistors en parallèle, on obtient de la mémoire NOR (dont le nom provient lui-aussi de l’analogie avec les portes NOR, où les deux transistors sont en parallèle).
Les deux types de mémoire ont chacun leurs avantages : la NOR est plus rapide mais la NAND permet une densité d’information plus importante.
Elles ont des applications différentes également : la mémoire NOR est utilisée quand la quantité d’information à stocker n’est pas grande ou bien si la vitesse est cruciale : mémoire cache des CPU (très rapide) ou mémoire des systèmes embarqués, par exemple. La mémoire NAND est utilisée dans les disques durs SSD, les clés USB et les cartes mémoire, là où la densité d’information est un facteur (commercial) important.
Un googol est un nombre représentant une quantité, tout comme les quantités « dizaine » ou « centaine ». La particularité ici est que le googol est un nombre plutôt grand puisque c’est un 1 suivi de cent zéros.
On peut l’écrire et ça donne ceci : 10 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000.
Mais pour des raisons évidentes, on l’écrit plutôt sous sa forme exponentielle : $10^{100}$.
Ce nombre est plus grand que le nombre d’atomes dans l’univers, qui est estimé à $10^{80}$.
Pour voir la grandeur de ce nombre, on peut par exemple utiliser les combinaisons ou les arrangements. Par exemple, en essayant de dénombrer toutes les parties possibles pour un jeu d’échec. Ce nombre a été calculé et vaut environ $10^{120}$, soit 100 milliards de milliards de googol.
C’est pas mal, non ?
Mais il y a mieux. Il y a le googolplex.
Un googolplex est un nombre encore plus grand : c’est un 1 suivi d’un googol de zéros. Un 1 suivi de $10^{100}$ zéros.
Je vous le dis tout de suite : il n’y a rien qui puisse être compté en googolplex. Ce nombre ne sert pas à grand chose, mais il est intéressant quand même, surtout quand on essaye de l’écrire (comme j’ai fait pour le googol un peu plus haut).
En fait, je vous laissez l’écrire en entier, moi je n’y arriverai pas.
Non, vraiment, je vous regarde.
Voici pourquoi je vous laisse faire : un googolplex est un nombre si immense que rien que pour l’écrire, le nombre d’atomes dans l’univers ne suffit pas. Il y plus de « 0 » dans l’écriture de ce nombre que d’atomes dans l’univers. Il faudrait environ cent milliard de milliard d’univers comme le nôtre pour avoir un atome par « 0 ».
Et encore, soyons bien clairs : tout ceci ne servira que pour écrire le googolplex ; et ça ne représente pas le googolplex lui-même !
La seule représentation possible, c’est celle avec les puissances : $10^{googol}$ ou $10^{10^{100}}$.
On peut également l’écrire de façon plus remarquable $10^{10^{10^{2}}}$.
Enfin, comme si ça ne suffisait pas, le googolplex n’est pas le plus grand nombre imaginé ou encore nommé.
Ok, il suffirait de parler de « deux googolplex » pour en faire un plus grand, mais d’autres nombres tels que le nombre de Graham ou le nombre de Skewes sont bien plus grands (mais moins marrants à prononcer, c’est vrai).
Oh et pour le dire : l’entreprise « Google » tire son nom de ce nombre, et le siège social de Google se nomme le Googleplex aussi. Mais ces derniers n’ont rien inventé de ce côté là :).